Using Large Language Models and AI Agents to Create an Index Biblicus Scholasticus
Intro
Recently, I’ve been really interested in indices because I think they contain huge potential for comparison and discovery across a corpus and through time. (See for example my earlier post: Indices and Classification)
I’m also interested in indices because – from a very Marshall McLuh-ian perspective – I think this immense potential for research largely lies fallow because of the dominant media (and inherited workflow) through which we build, publish, and use these indices.
From my perspective, there are at least two major problems.
First, the way we normally document sources or citations in historical editions, and subsequently create indices, is an incredibly laborious process that simply does not scale fast enough to match the overwhelming size of the corpus.
Secondly, the way we publish and store the results of this work, in static lists referring to imprecise page numbers and fragmented into individual physical volumes, means that, despite, all this hard work, we can barely scratch the surface of their potential for comparison and discovery.
Recent advances in AI and AI agents offer potential to overcome these problems.
But this is also an opportunity to pinpoint what exactly it means to use AI in critical editing and what it takes to do it well.
Here I think it is useful to contextualize this discussion against a certain understandable and often justified AI skepticism.
Most people’s experience of AI is using some kind of AI chatbot, like ChatGPT, Gemini, or Copilot in some kind of web interface.
The initial experience is kind of interesting, even fascinating, but then it is time to get back to work. And if you think of your job as a critical editor correcting texts in a Word document, marking quotations with quotation marks, and then adding human readable footnotes at the bottom of each page to identify those sources, then it is not too hard to understand why you might think the AI hype is overblown.
Beyond being a kind of souped-up Google search, the AI chatbot doesn’t really change your work very much. The responses it gives are sometimes correct, but just as often they are imprecise, imperfect, or just wrong. Using the tool requires a lot of copying and pasting and doesn’t feel like a dramatic time saver. It might be a useful tool, but it is certainly not a game changer.
I completely understand this attitude.
But if I can pinpoint a little thesis, it is this:
that to understand how AI agents can assist us as critical editors and as researchers in a “revolutionary” way, we have to “revolutionize” the way we think it means to make and publish an “edition”.
Let me restate this in a second way:
if we continue to treat critical editions as isolated, fixed presentations of texts-books or standalone websites-we will not be able to scale our access to the historical record.
To take full advantage of modern computational and AI tools, we need to move away from thinking of editions as finished, static presentations to treating them as shared layers of structured data that are continuously open to use, reuse, and extension.
If what I mean by “shared layers of structured data that are continuously open to use, reuse, and extension” or why this feels so urgent to me is still fuzzy, that’s okay.
What I’d like to do now is show you how I’ve been able to use AI agents to drastically scale the marking of sources within the scholastic corpus – with a special focus on biblical reception.
But as I do this, I want to try to emphasize why this works for me. I want to emphasize all of the scaffolding that already has to be built and put in place in order for me to get these kinds of results.
It is this “revolution” of thinking about what it means to edit and publish historical text that is allowing me to get “revolutionary” results.
Part 1: A GPS for Texts
I will briefly summarize this because the precise details are not so important. I simply want to illustrate how I’m thinking about texts and citations differently.
The traditional approach to identifying sources has been to record references using strings of containers.
Frequently a material hierarchy reference (e.g. “1959 edition, volume 35, p. 123”) is used to provide granularity. And this is why we see indices filled with page numbers.
But there are a number of problems here.
- First, these actually are not that granular. Where on page 55 exactly is this reference?
- Second, such a reference is obviously tethered to the current physical volume. The references become useless the moment the text appears in a new environment and they offer us no help identifying that reference in another witness.
- Third, references through coarse page numbers lose incredibly important contextual information. If I want to know how citation patterns change from section to section or question to question, a reference location on page 24, 100, and 450 tells me none of this information.
In contrast, we need to think about our corpus as a giant pool of granular and identifiable fragments of text, that share hierarchical and non-hierarchical relationships with one another.

This means that it should be possible to create an identifier that can single out any division, paragraph, quotation, or even any word – independent and apart from any particular material hierarchy it might inhabit or any particular material page or website on which it might be found.
This is not actually an unprecedented shift. We used to use containers to locate places on maps.
We first had to know: what state is it in? What county is it in? what city is it in?
Only then could we look in a particular witness to that map and say: Which volume is it in? Which page is that on? What grid quadrant is that in?
But we don’t do that anymore. Now we have GPS coordinates that create unique identifiers for a place abstracted from any particular map book – abstracted from any particular presentation.
We supply the id, and then the “view” is constructed automatically by resolving the identifier and then requesting its connected hierarchical relationships. These hierarchical relationships are then used to locate a particular witness and then used to locate a specific coordinate space with that material artifact.
We need to create a gps system for our texts.
To do this we need to mint identifiers for each part of the text (in all of its witnesses) and then record the kinds of relationships it has.
Very quickly, here is a glimpse of what that looks like.

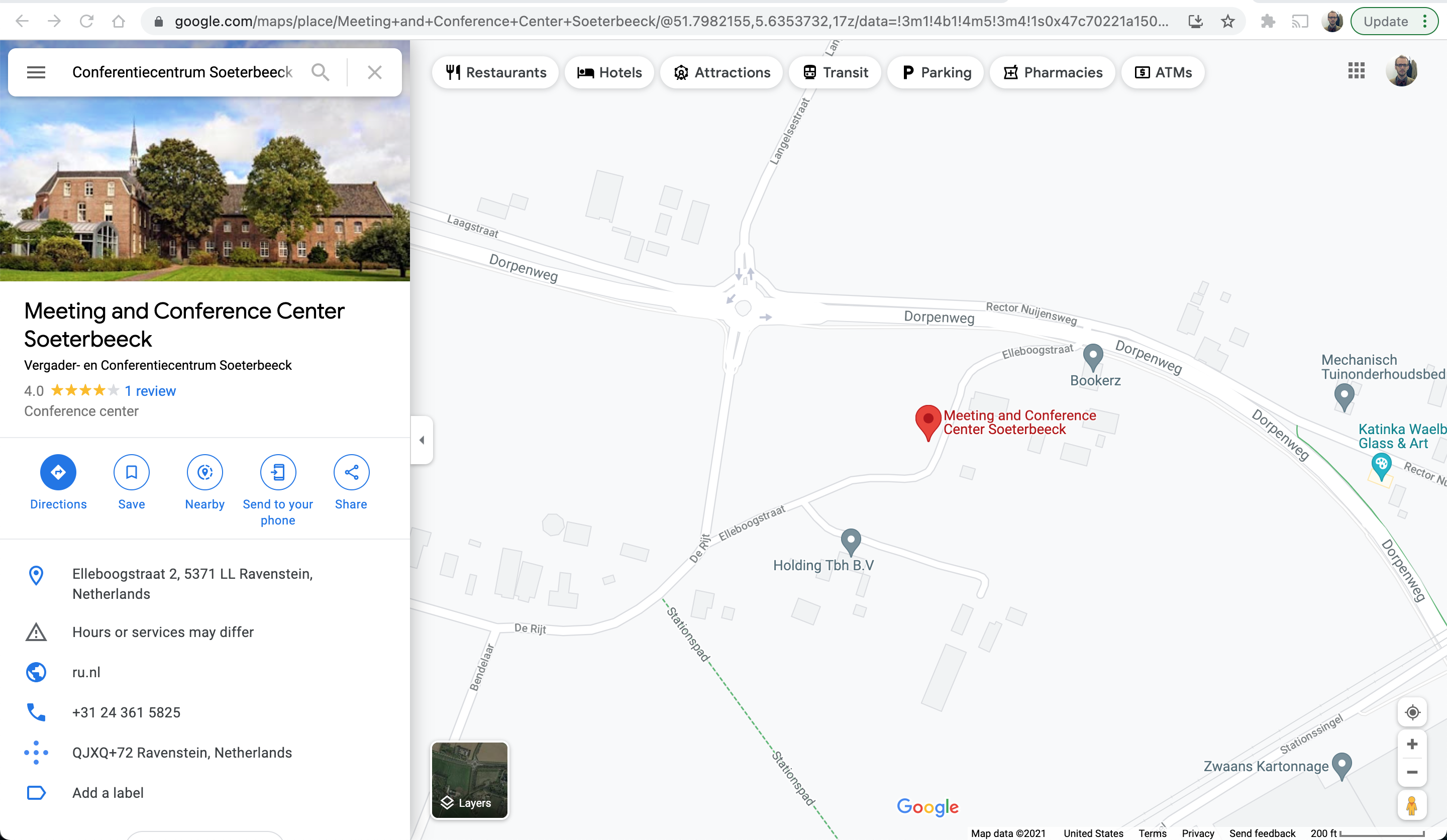
Every text can be described at three levels, as an abstract idea (an expression), as a manifestation of that expression, and then a transcription of that manifestation. And this division occurs all the way down the text hierarchy from the top level of the work down to every paragraph and every quotation.
With this in place, individual transcriptions can be tethered via line breaks to the material hierarchy of a given manifestation…

…that is, to the coordinates of a given line on a specific image of a specific page.

Then we can bring this together.
Mapping transcriptions to their manifestation
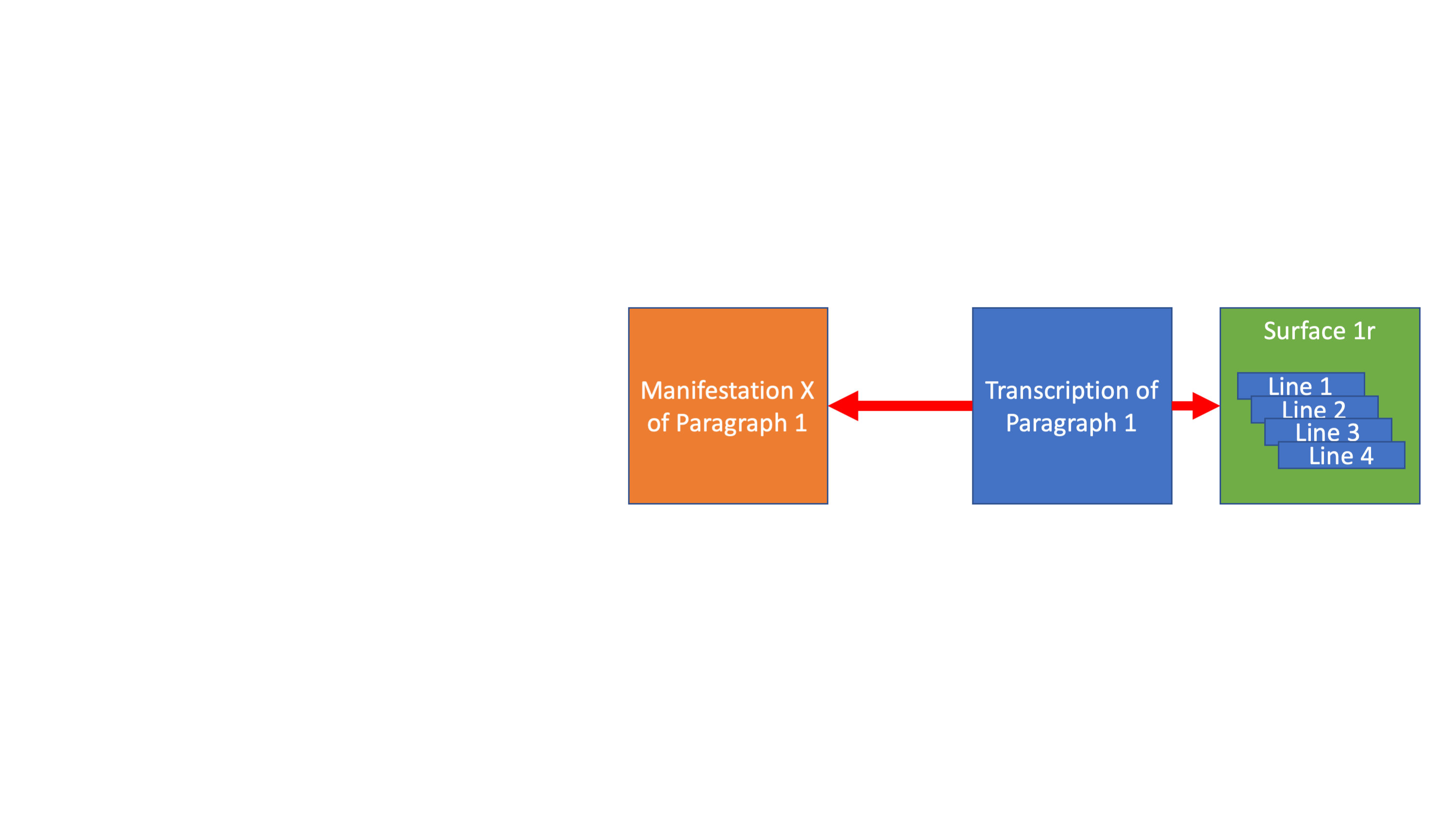
Mapping manifestations to abstract ideas of texts (expressions)
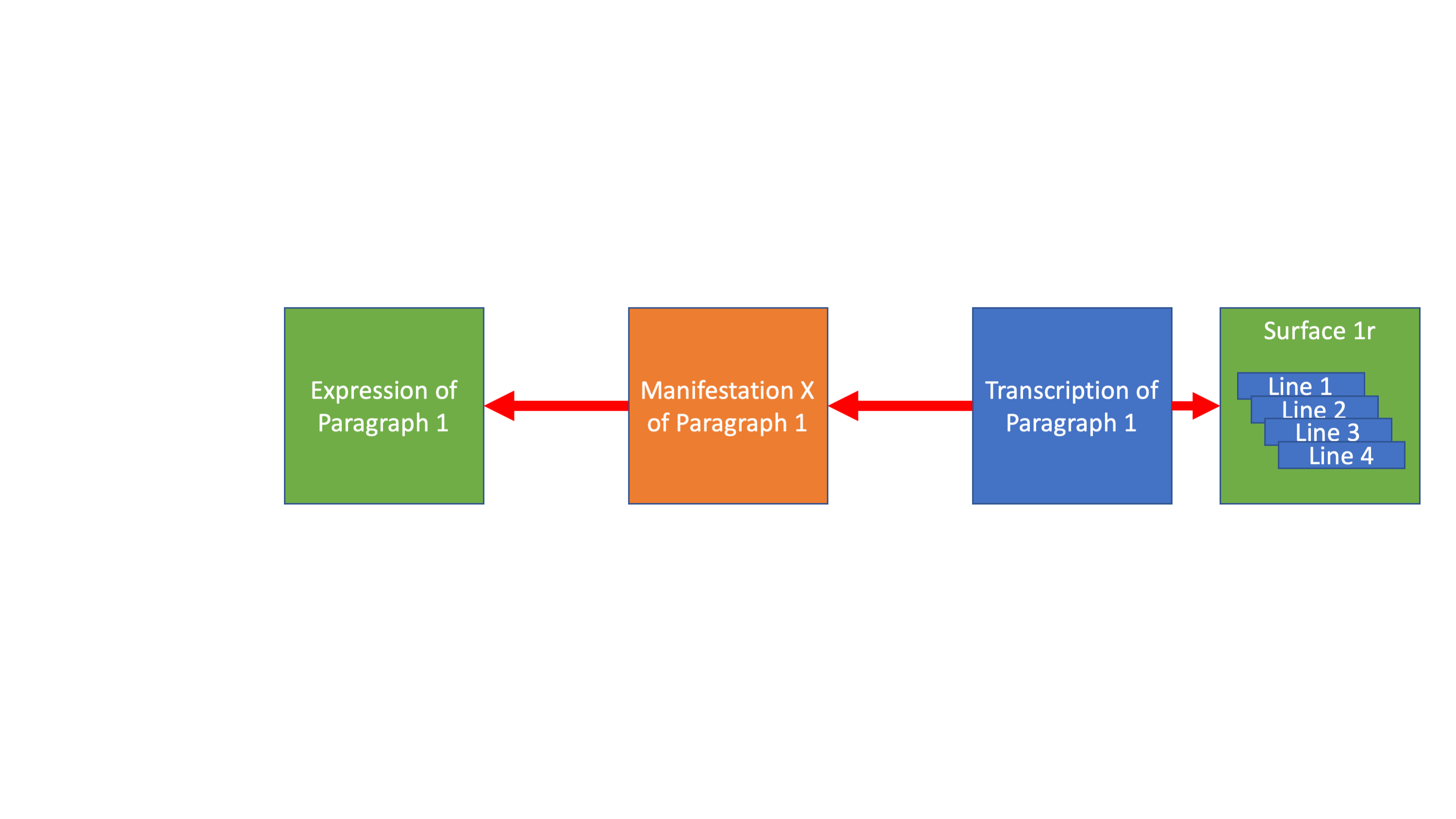
And then textual ideas can be mapped back out to their other witnesses
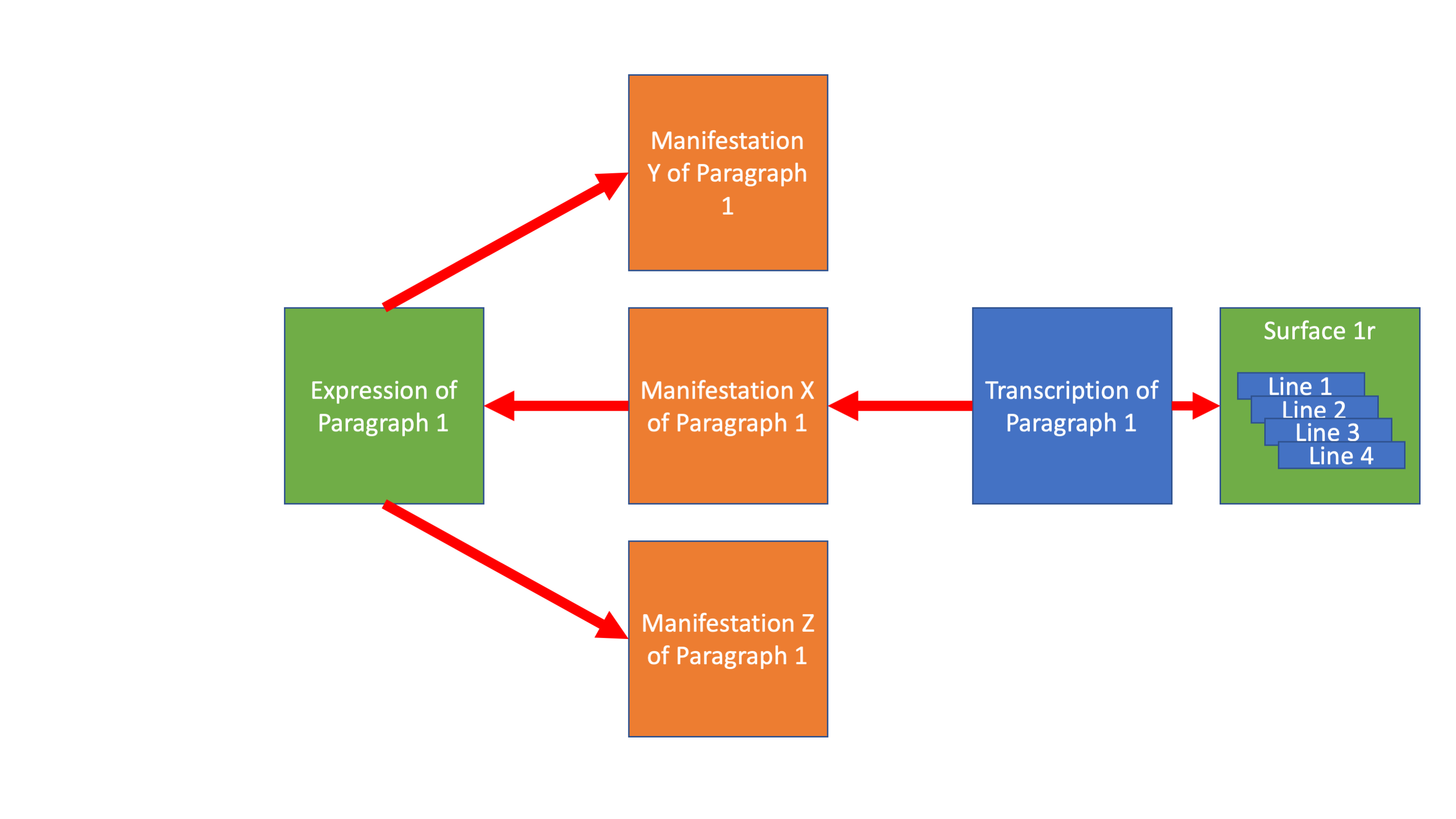
And these witnesses to their own transcriptions
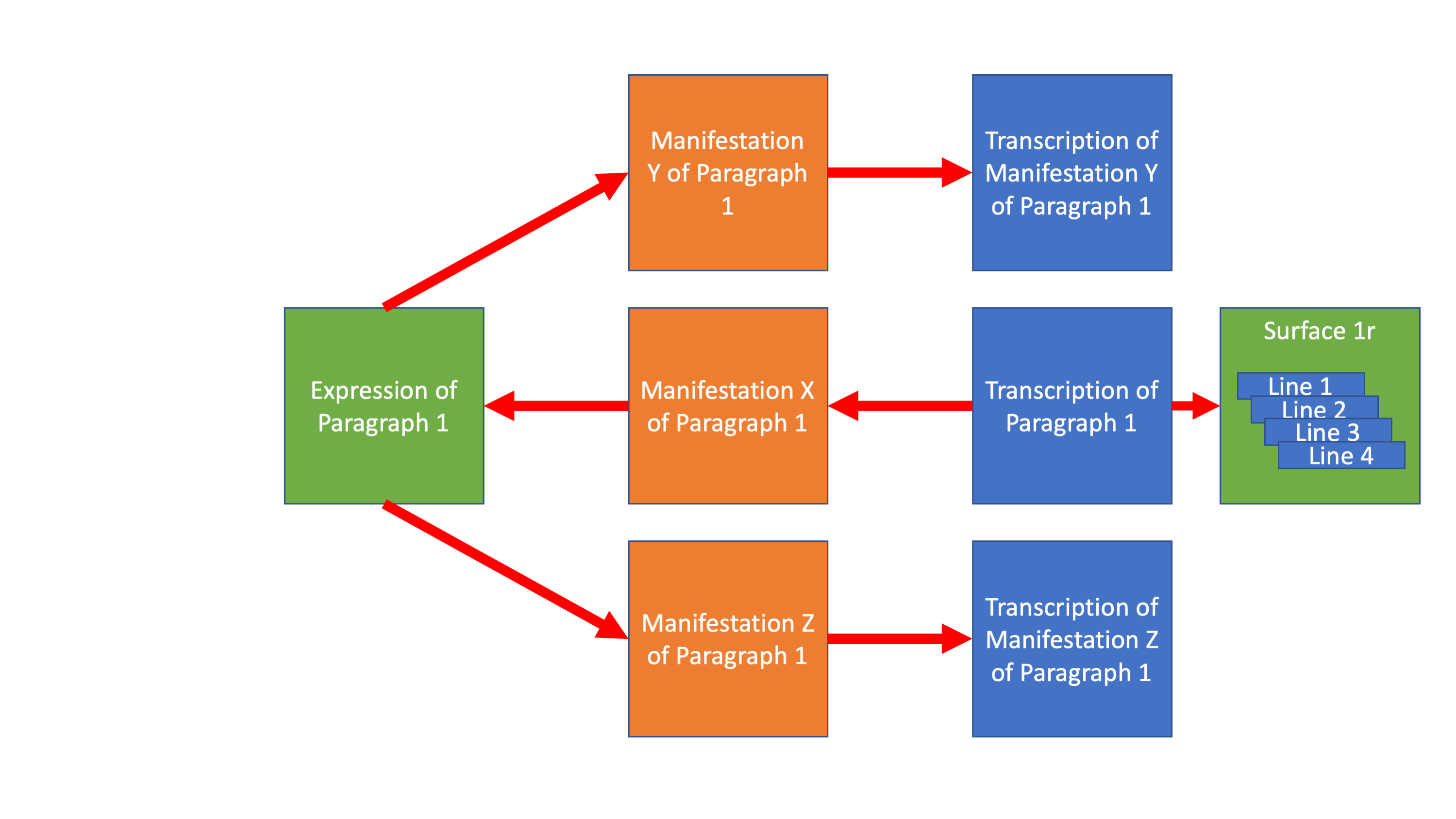
And these transcriptions to the images of these witnesses

And then when one textual idea quotes another textual idea, we can link these together.

Suddenly we have a network that allows us to start on the fragment image of a given quotation in a specific witness and not only walk out to all the other witnesses of that same quotation, but also to walk out to the source text of that quotation and then to all its witnesses.
We can look at this more concretely.
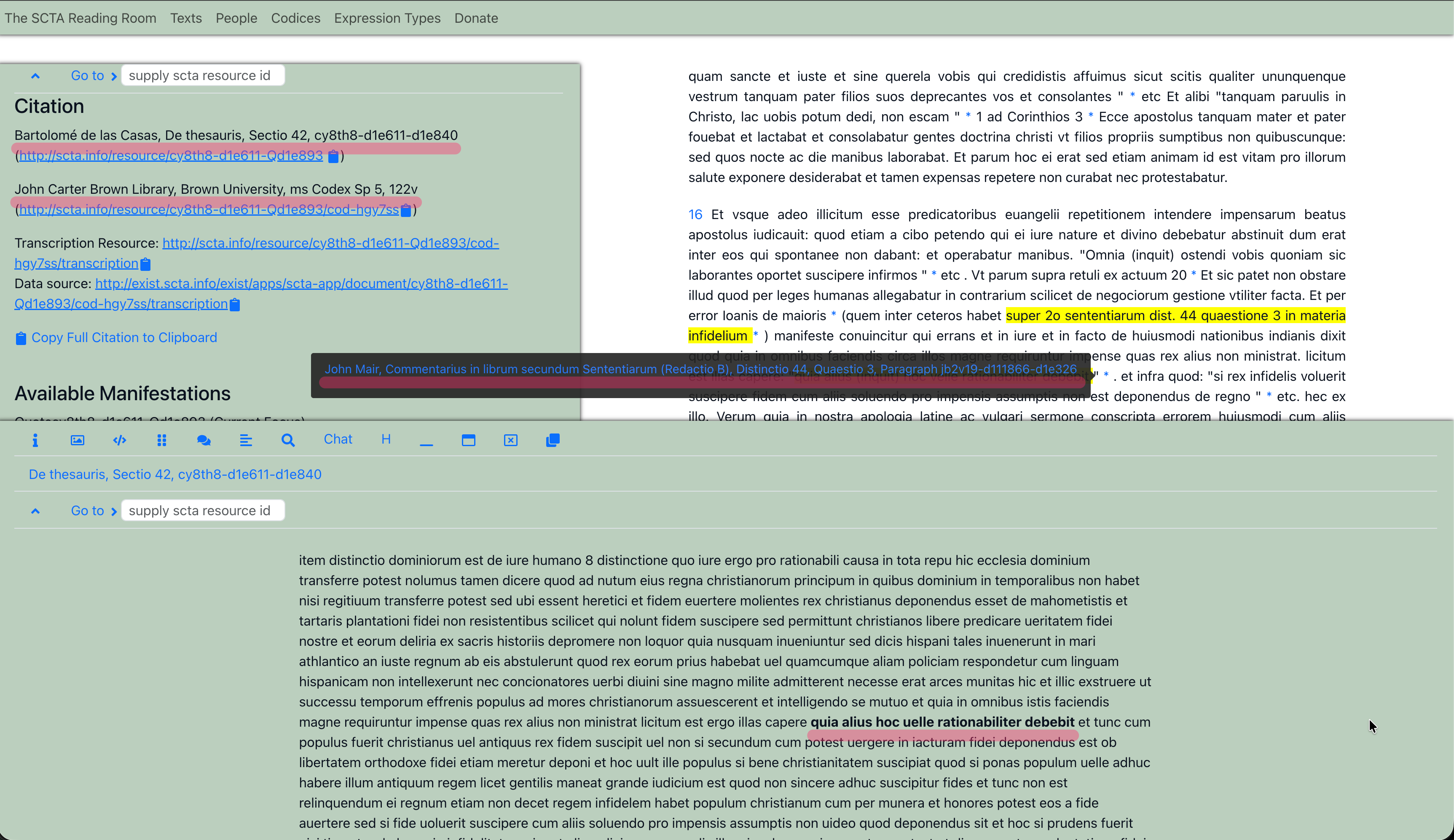
Here we can see the text of Bartolome de Las Casas, De thesauris, section 42, where he quotes the Parisian Theologian John Mair.
As we can see on the left, when we focus our attention on the quotation made by Las Casas, the reference to where we are in the text and where we are in the specific witness to the text is automatically constructed.
And when we click on the quotation to see the source, the identifier for the John Mair text is also automatically constructed.
But this is also not just a reference that a human has to resolve. Instead, because it is a unique identifier, the system can resolve it, and the precise passage of John Mair quoted by Las Casas is retrieved from the common pool of text and presented to the user in bold (surrounded by its immediate context).
The same auto-construction of citations can happen in any viewer or data presentation. Here we can see the Mair citation auto-constructed in a print layout of the text.

Part 2: Using our Text GPS system
So now marking and identifying sources means something different. It doesn’t mean creating a footnote with a human readable string of containers.
It means asserting a data-link between uniquely identifiable text fragments.
What our AI agent needs to do.
- request a paragraph fragment from the pool of data using its unique identifier
- request a candidate bible verse fragment from the pool of data using its unique identifier
- make a decision about whether the bible verse really is quoted within that paragraph
- if present, identify the quoting fragment of paragraph and mint a new unique identifier
- if present, identify the quoted fragment of the bible verse (e.g. words 4-11)
- link the quoting fragment to the quoted fragment.
Imagine just giving this task list to a web based chatbot. It wouldn’t be able to do anything. It doesn’t know how to reliably retrieve these fragment texts and it doesn’t have access to unique identifiers for these texts.
What we need to do is build up a set of services, where the unique identifiers can be discovered and used and then raw text can be received in return.
Defining these services is a huge part of what allows AI agents to work successfully. These services are defined by something called the Model Context Protocol (or an MCP server.)
In the code snippet below, there is a property called “tools”. Underneath this are several available tools, the most important for the moment is the “textLookup” service.
{
"name": "textLookup",
"description": "Retrieves the text content for a given SCTA resource identifier.",
"input_schema": {
"type": "object",
"properties": {
"resourceId": {
"type": "string",
"description": "The SCTA resource identifier. Can be a full URL (e.g., 'http://scta.info/resource/rom1_1') or a short ID (e.g., 'rom1_1')."
}
},
"required": ["resourceId"]
},
"output_schema": {
"type": "object",
"properties": {
"resourceId": {
"type": "string",
"description": "The full SCTA resource ID"
},
"text": {
"type": "string",
"description": "The text content of the resource"
}
}
},
"endpoint": "http://localhost:3001/textLookup",
"method": "POST"
}
In short, this service describes the inputs that must be given in order to receive the outputs. As input, you supply a resourceId, and as output the service returns the text content that corresponds to this resource.
Now, we could (I guess) ask an AI agent to just start requesting every paragraph in the corpus, (close to a million paragraphs) and then for each paragraph request every bible verse to decide if a bible verse has been quoted.
But this is incredibly inefficient and in a world where frontier LLM models are rate-limited, this inefficiency has heavy costs.
So, we have to add more scaffolding in order to assist with this process.
Fortunately, we can use some pre-processing steps with traditional Natural Language Processing techniques to identify candidate Bible verses that are highly likely to be found in a given paragraph.
Here we can see a visualization of this step, with each bible verse in Romans listed across the X-axis and any paragraph in the entire corpus that shares significant amounts of textual overlap indicated with a red dot running down the Y-Axis for the corresponding bible verse.
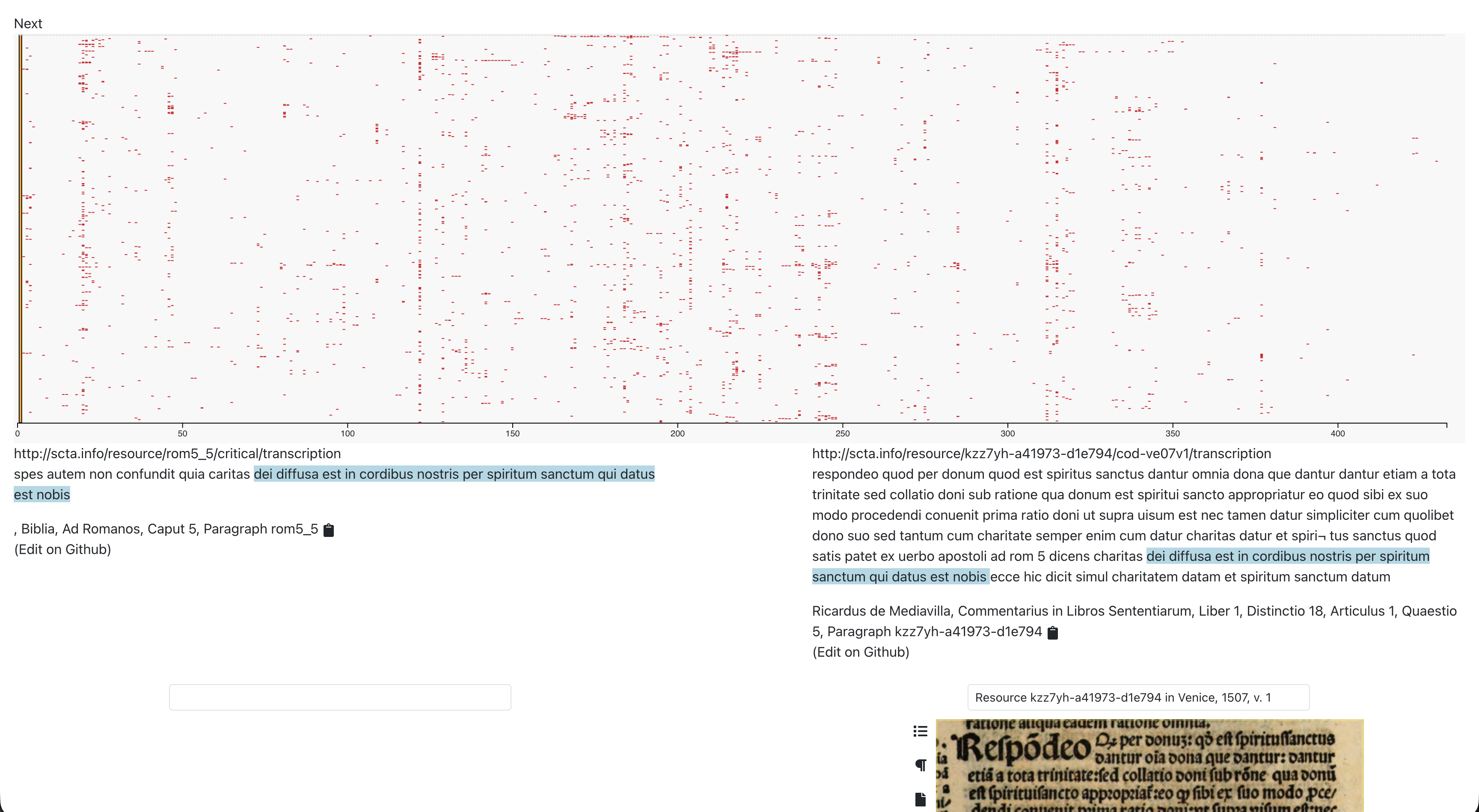
This visualization was made for humans, but what we really need is the data version underneath this that can be read by LLM agent.
So this is another service we provide to our LLM in the form of a “bible_candidates_” file. This is our bible_candidates file.
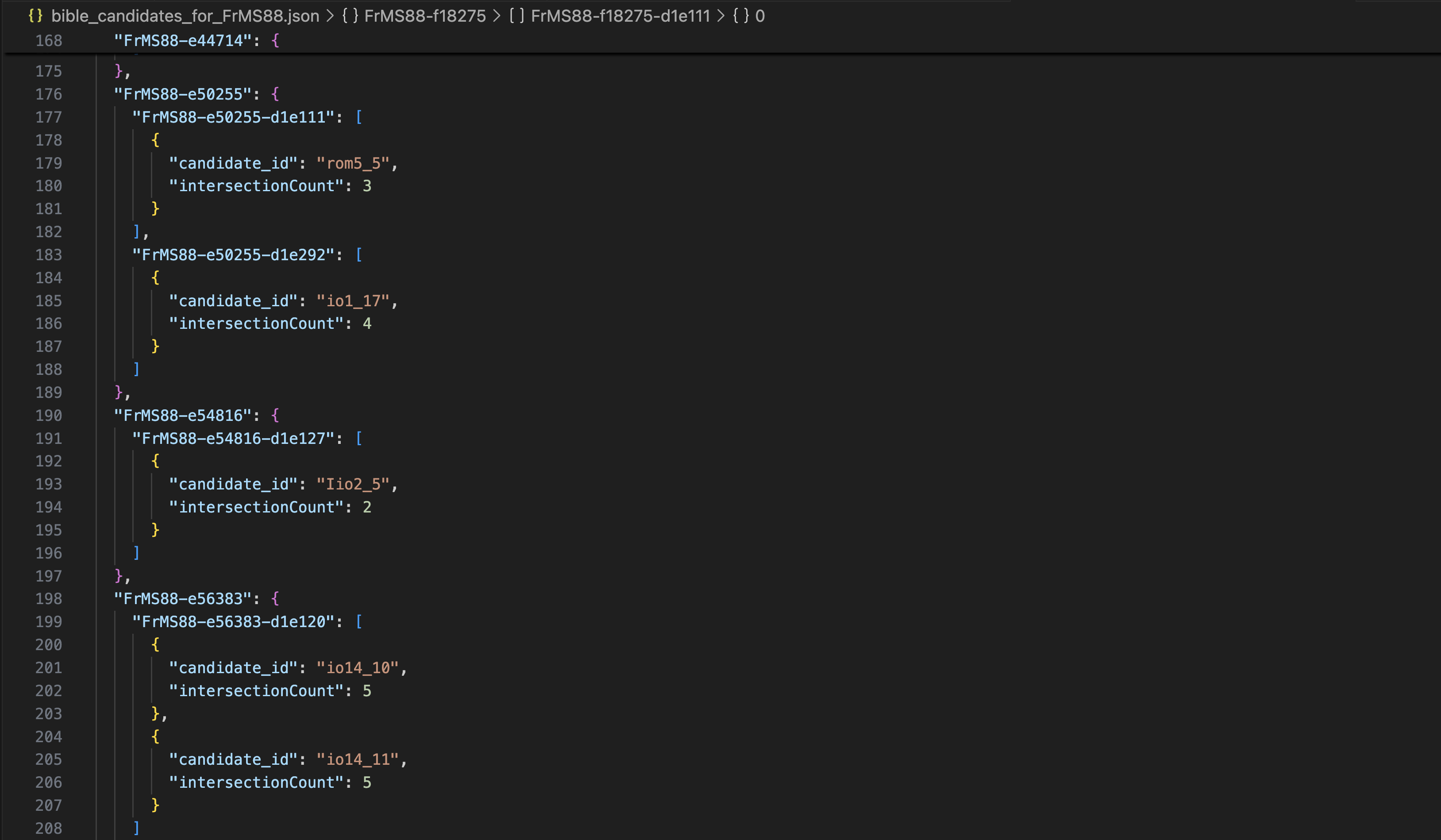
In this file, you can see the text GPS system at work.
We have a list of paragraph IDs, and then we have a list of candidate Bible verses for each paragraph along with a confidence score indicating the likelihood that this Bible verse is being quoted in this paragraph. The higher the number of textual overlaps, the more likely there is a genuine quotation here.
Now the LLM can read the “candidates file,” use the information in this file to write a query according to the input schema of the textLookup service, and receive both the quoting paragraph and the quoted Bible verse.
Now, after it has made a decision about whether the Bible verse is detected, it can use the textRangeIdentify service to reliably get the fragment of the Bible verse being quoted (for example words 5-10 of Romans 1).
{
"name": "textRangeIdentify",
"description": "Finds the token position range of a quote fragment within a source text identified by SCTA resource ID.",
"input_schema": {
"type": "object",
"properties": {
"resourceId": {
"type": "string",
"description": "The SCTA resource identifier. Can be a full URL (e.g., 'http://scta.info/resource/rom1_1') or a short ID (e.g., 'rom1_1')."
},
"quoteFragment": {
"type": "string",
"description": "The text fragment to locate within the source text."
}
},
"required": ["resourceId", "quoteFragment"]
},
"output_schema": {
"type": "object",
"properties": {
"resourceId": {
"type": "string",
"description": "The full SCTA resource ID"
},
"quoteFragment": {
"type": "string",
"description": "The quote fragment searched for"
},
"start": {
"type": "number",
"description": "Starting token position (1-indexed)"
},
"end": {
"type": "number",
"description": "Ending token position (1-indexed)"
},
"found": {
"type": "boolean",
"description": "Whether the quote fragment was found"
}
}
},
"endpoint": "http://localhost:3001/textRangeIdentify",
"method": "POST"
}
Finally, in addition to creating all these services, we need to document the workflow I’ve just described as a kind of recipe that an LLM agent can use to orchestrate and bring all these services together in harmony.
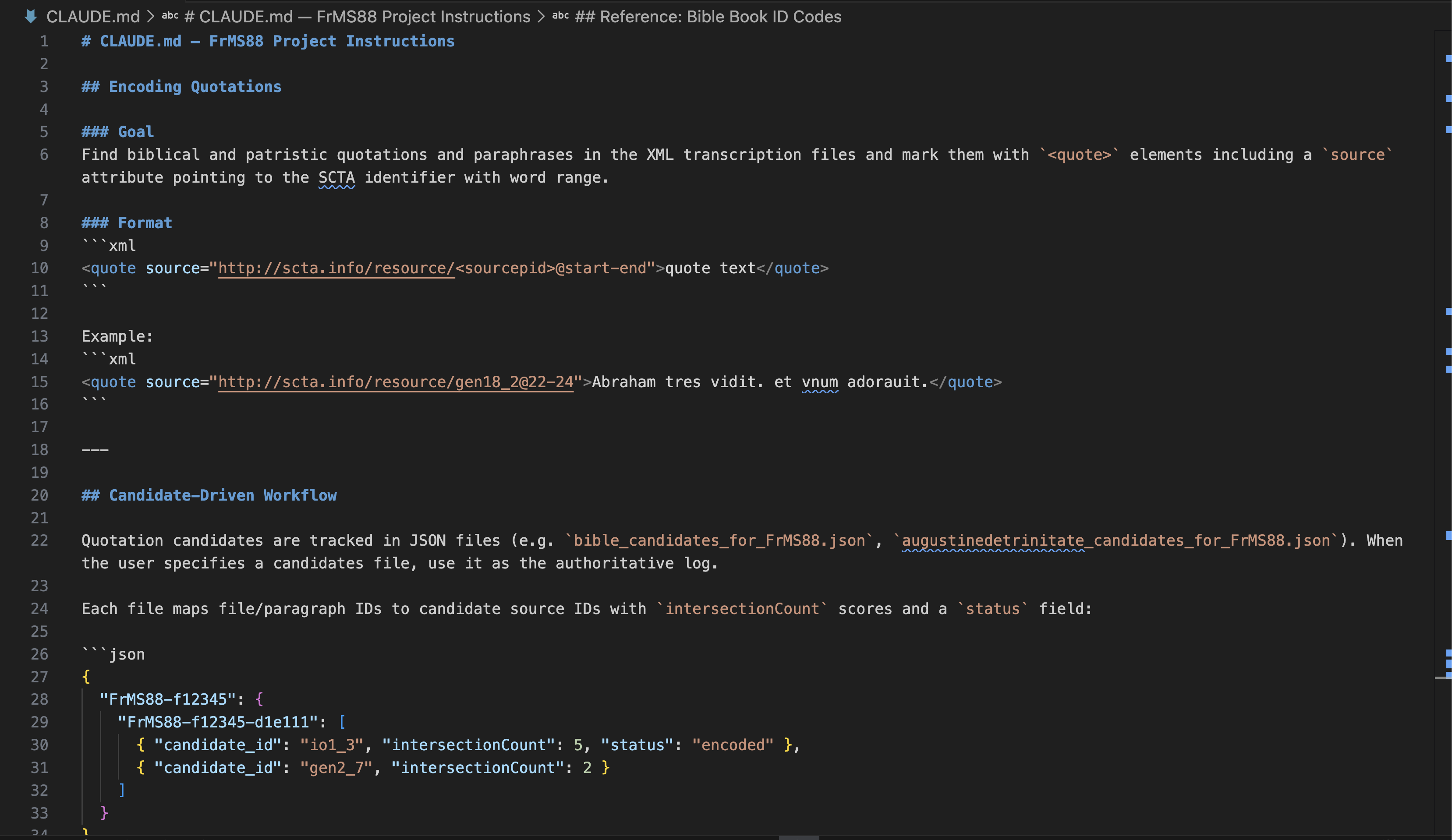
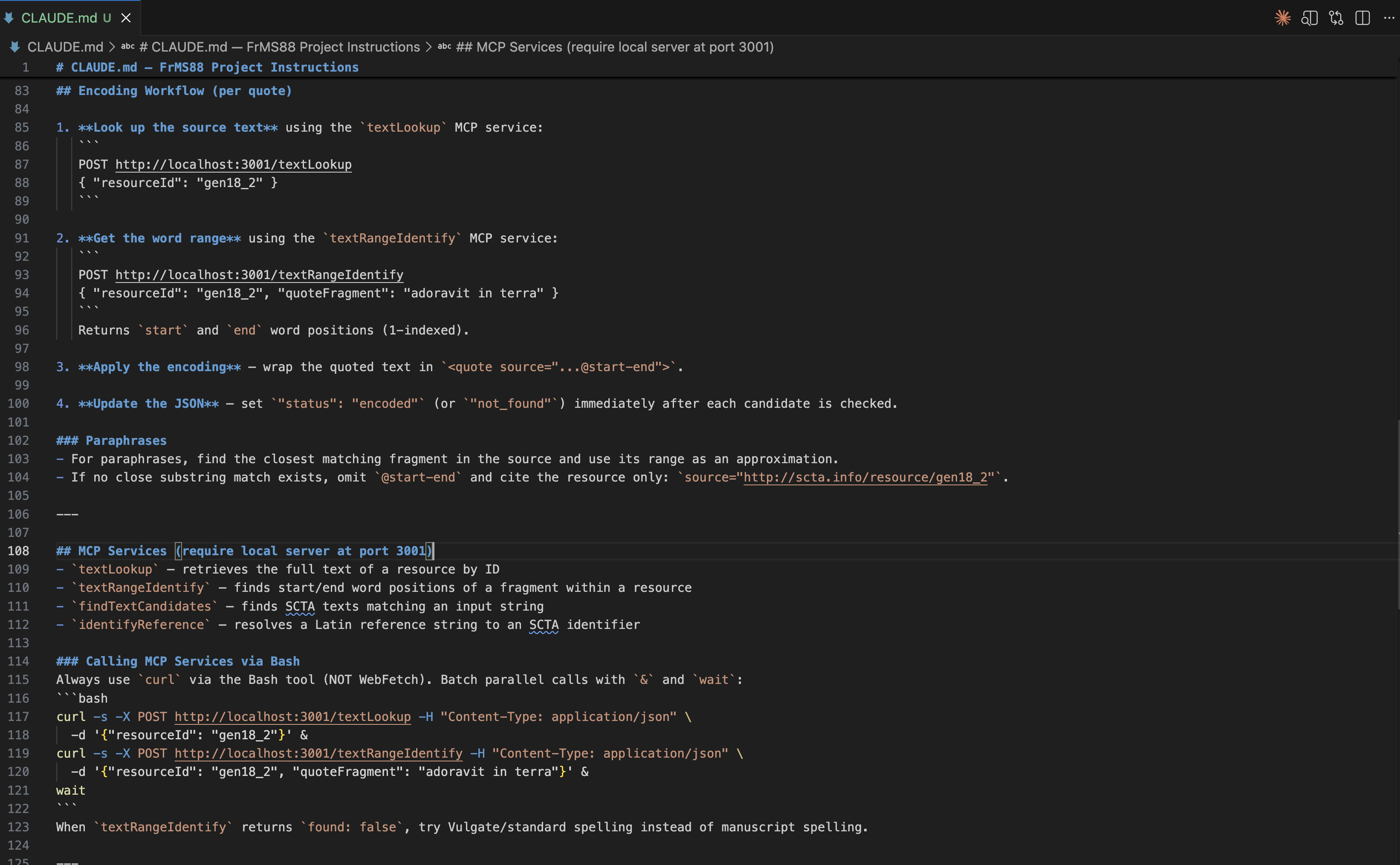
In Agentic platforms (like Claude Code), these “recipes” are often referred to as SKILLS and this skill is called /encode-quotes.
When we put this all together, we can actually get something very useful.
Results are encouraging.
Over the last 10 or so years, little by little, I’ve manually marked about 8,000 Bible quotes.
In a little over a month, with this new AI-assisted workflow, I’ve marked an additional 10,000 bible quotations.
With a corpus of nearly 60 million words prepared, we have well over 100,000 Bible verse candidates.
At the current pace, I expect to have over 100,000 marked in less than a year, representing an index of biblical reception in the scholastic tradition (both medieval and modern) on the scale of the Biblia Patristica.
And the only reason for this extended timeline is the rate-limiting of these LLM providers. On the $20 a month plan, I only have so many tokens to use per week.
On an unlimited plan, we could run agents in parallel and have an index of this scale done within the week.
But the time horizon of a year is not that big a deal. We have many more texts to add to the corpus, and the ability to mark these quotations will eventually surpass the speed at which I can prepare these texts. (Though this bottleneck itself is something I hope, with the right scaffolding, to have AI agents help me speed up.)
Part 3: The power of the index
But now let me conclude by returning to the second deficiency of traditional index practice.
The use of an AI agent can dramatically speed up the labor that it takes to create such an index.
But the way we are using the agent to mark these sources with machine actionable IDs rather than a human readable string also revolutionizes what we can do with this information.
In this regard, I am particularly interested in using a connected corpus wide index (rather than fragmented indices we get from indices tethered to individual physical volumes) to create comparisons, and from these comparisons to create recommendations and discoveries.
The value of such a recommender system for research has long been recognized in the field. We can see the aspiration to build such a system and offer recommendations in editions from the 15th century into the 19th and 20th centuries.

So, generally, I’m interested in using indices like these to build a recommender system for scholastic texts.
Think about the way Spotify recommends new songs based on the song you are currently hearing.
To do this the recommender system has to identify distinct signals that characterize or classify a song. Once it has this signal it can look for other songs that share a similar signal.
The way a text, or sub-texts, cites other texts and uses other texts, is a very strong signal.
Scanning the index is a good way to get a sense of what a book is about. Unfortunately, this manual analog method makes it almost impossible to compare signals.
(I guess we can get another book of the shelf, scan its index and get a rough sense of its similarity or difference, but this requires us to already know about the second book we are making a comparison to. It is not a very good approach for discovering something unexpected.
At the very least I hope you can see the immense potential here but also see how this manual method can never scale.
But now we can.
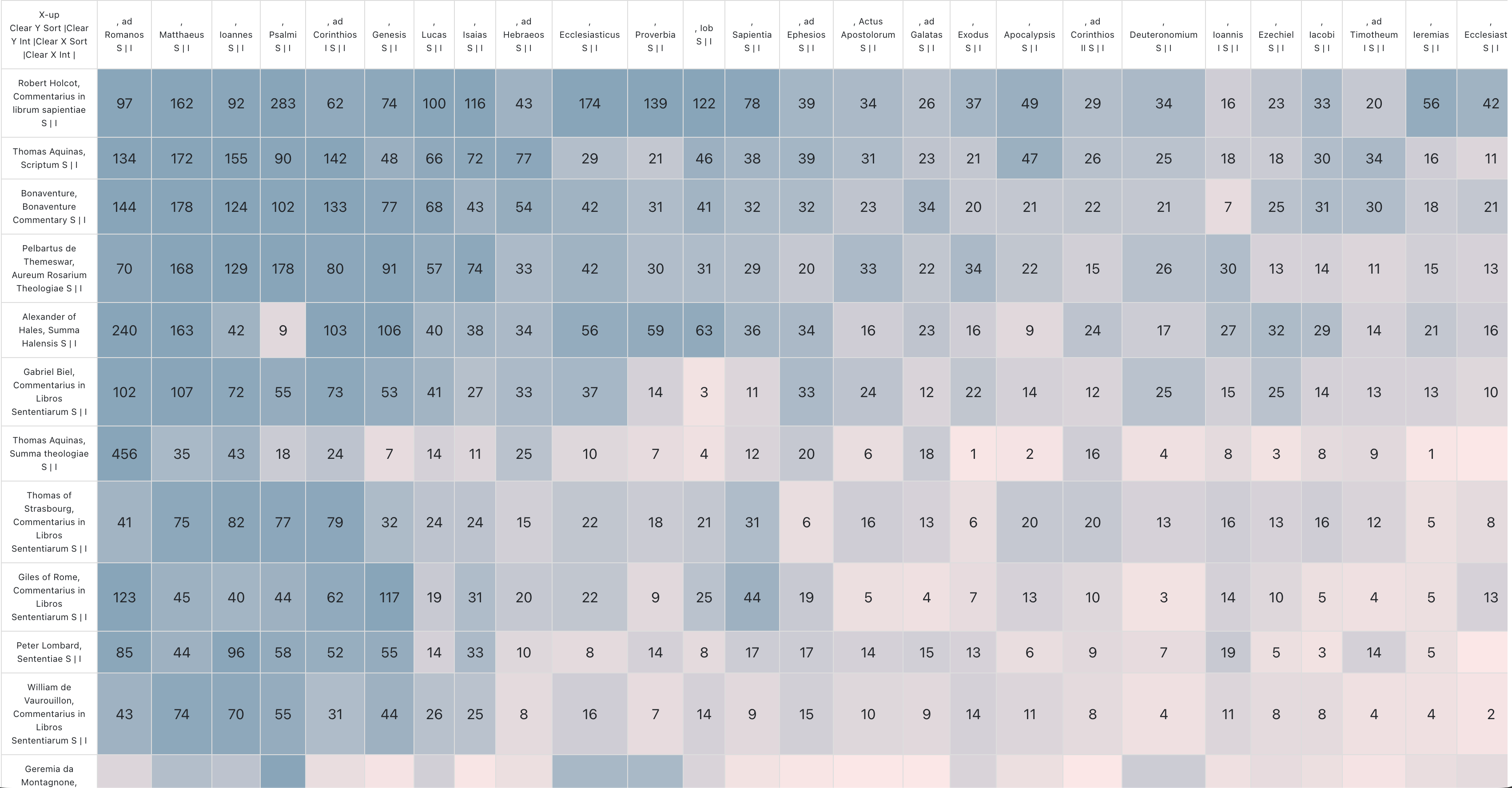
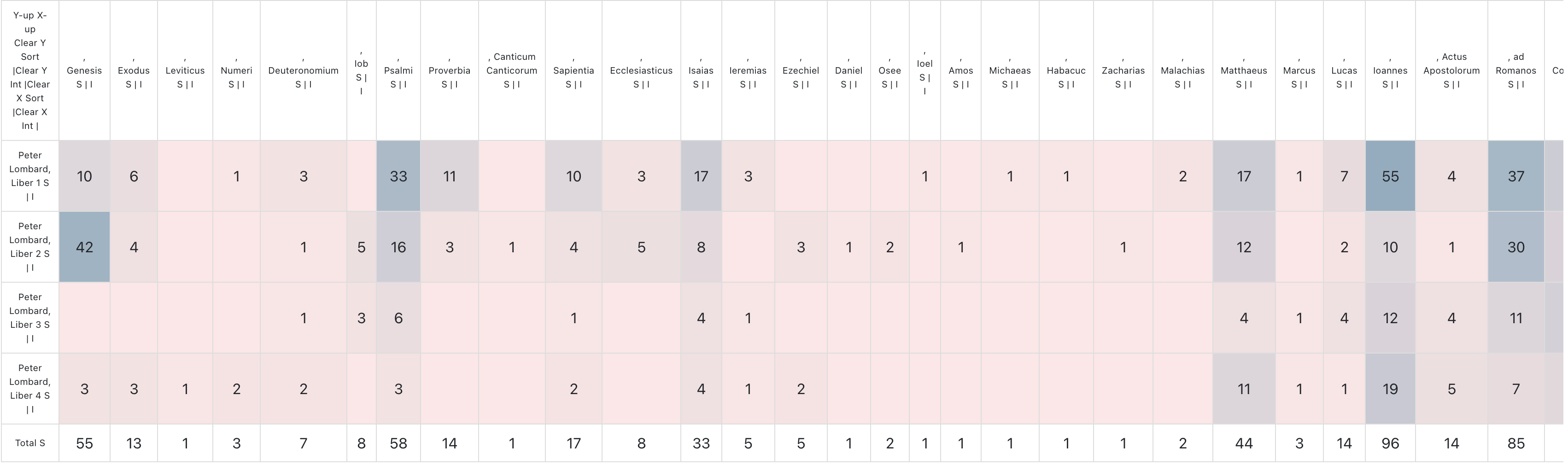
We can start to see a kind of signal emerging just comparing the frequency counts of citations for different biblical books
We can sort of see the different focus of each of Peter Lombard’s 4 books by seeing the different frequency of different books of the bible. (Note the heavy use of Genesis in Book 2, which is focused on Creation and the much weaker use in books 1,2, and 4)
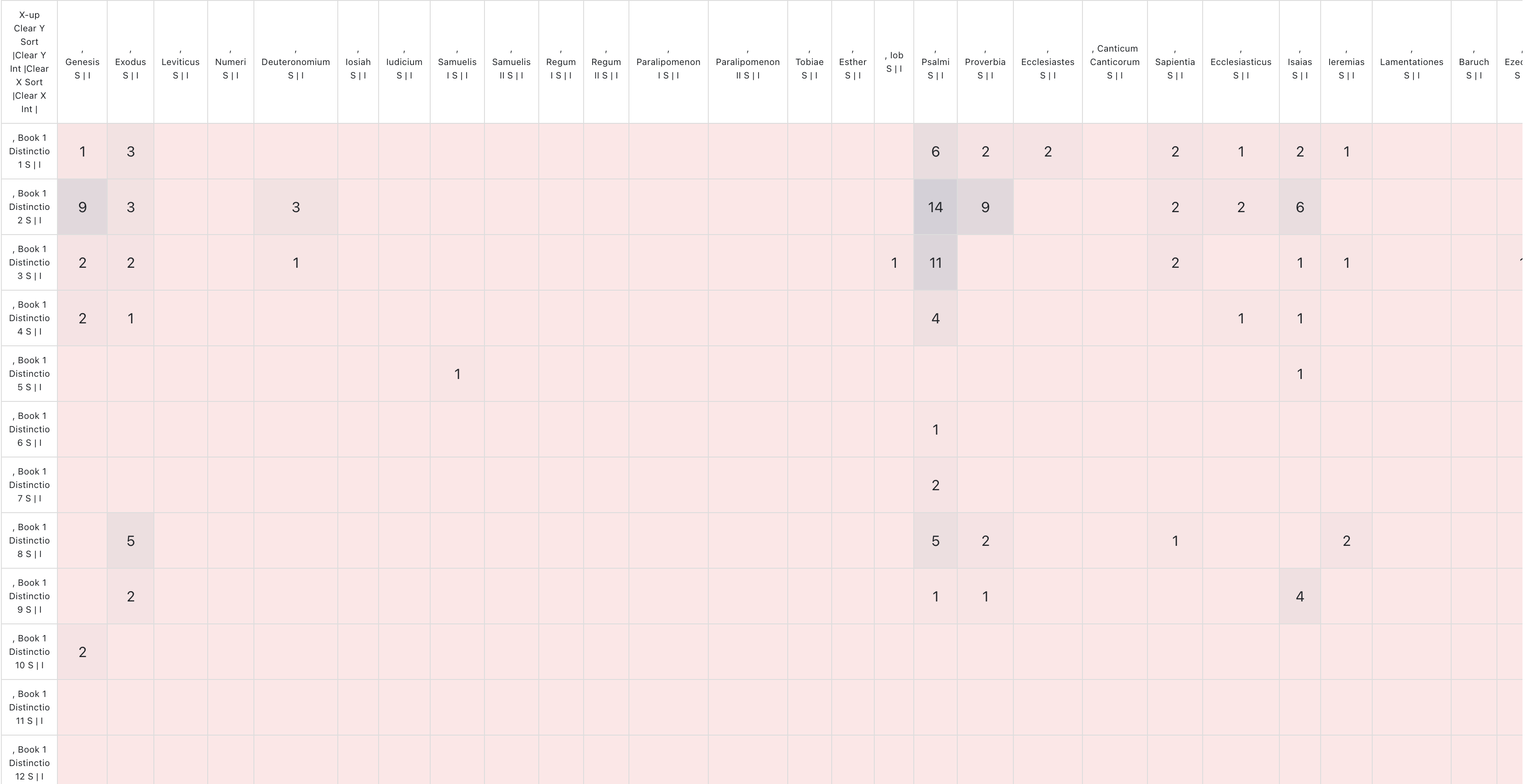
We could look at this for each distinction, but now it starts to get pretty overwhelming. So we need an algorithmic approach that can begin clustering texts based on the similarity of their citation signal.
Here we have dots represent chapters or scholastic questions, and they are clustered together based on the how many common bible citations they share.
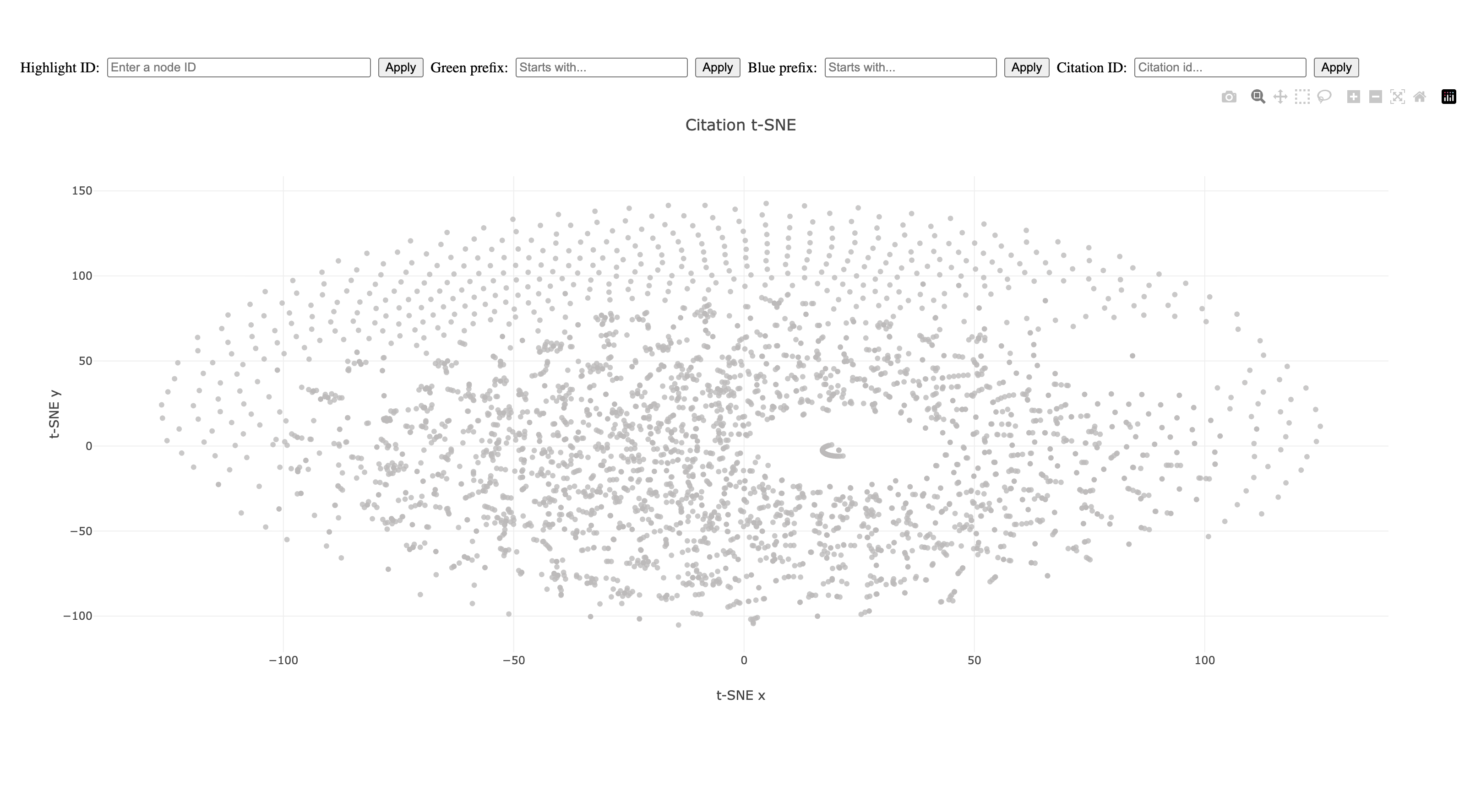
Consider two real-world scenarios where such a tool could be used.
Imagine working on the text of Bartolome de Las Casas and being interested in the medieval scholastic influence on his work, the Apologia.
First, all the chapters of this work could be highlighted.
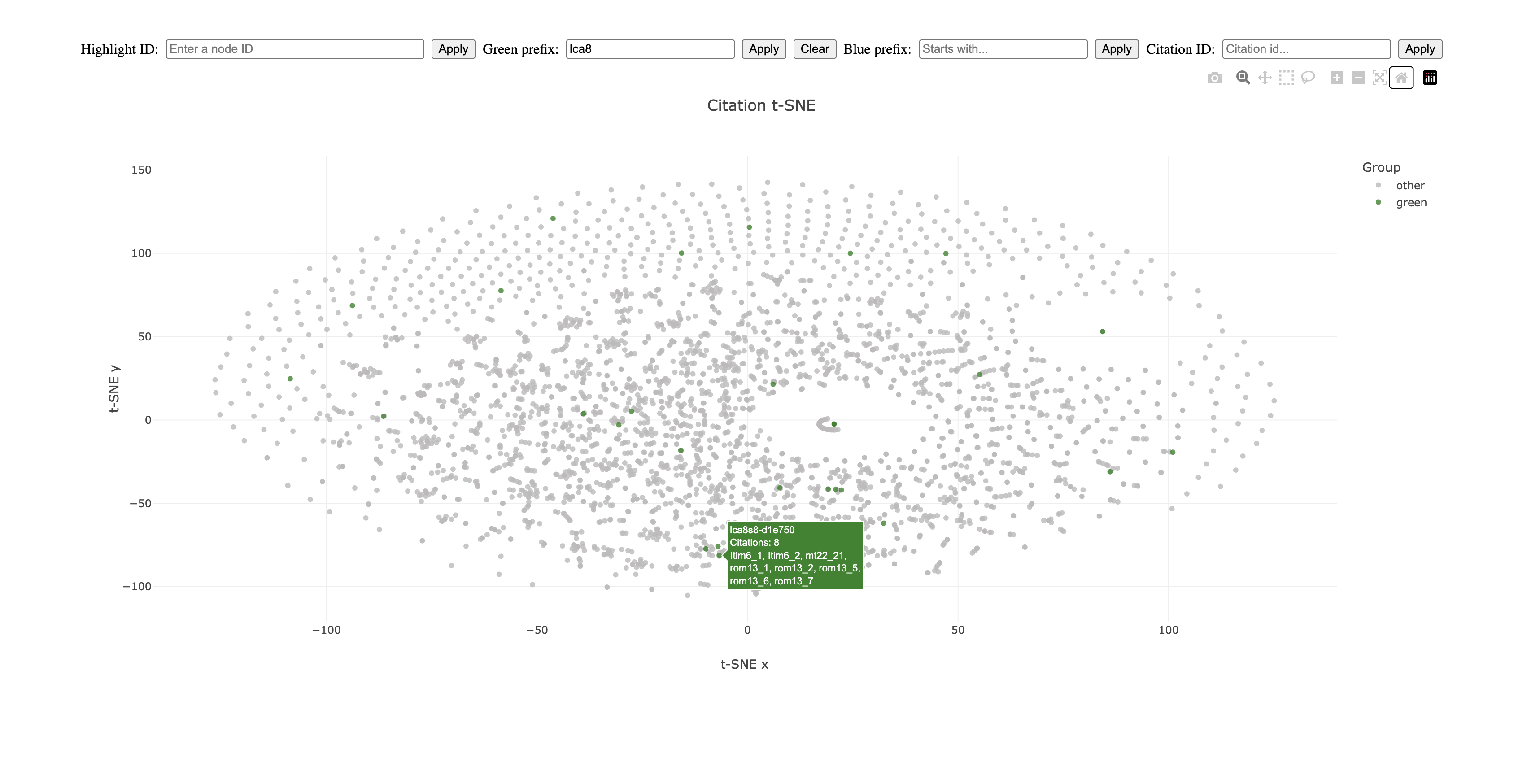
I could zoom in on one of these chapters and get a pretty good sense of what this chapter is about based on the question titles of the texts around it.
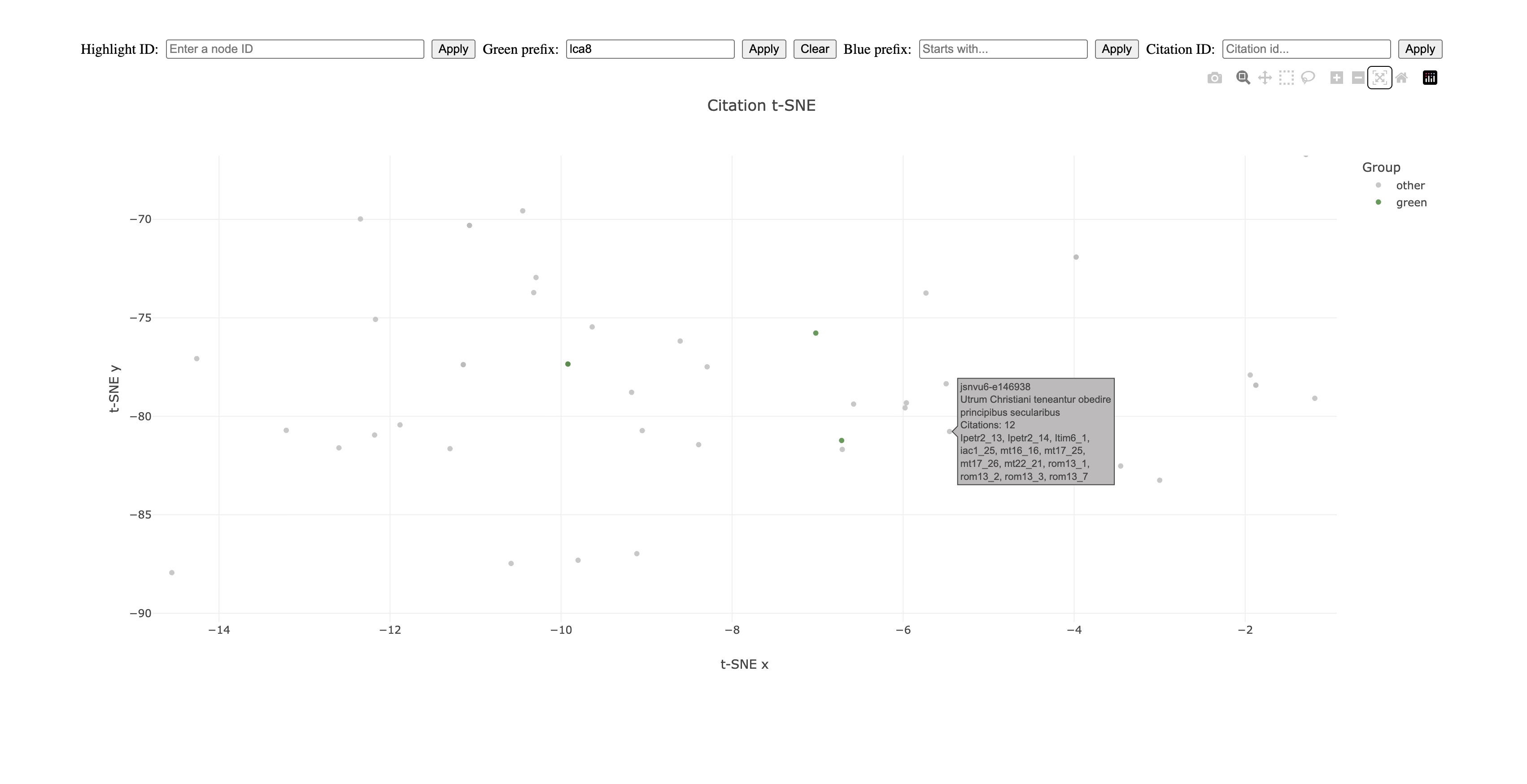
These are all medieval texts that have a lot to say about obedience to a governing authority and Las Casas is relying on the same bible verses that dominate in these earlier medieval discussions.
Second, we can flip this around and imagine that you are a Bible scholar interested in a particular verse, for example Romans 13:1.
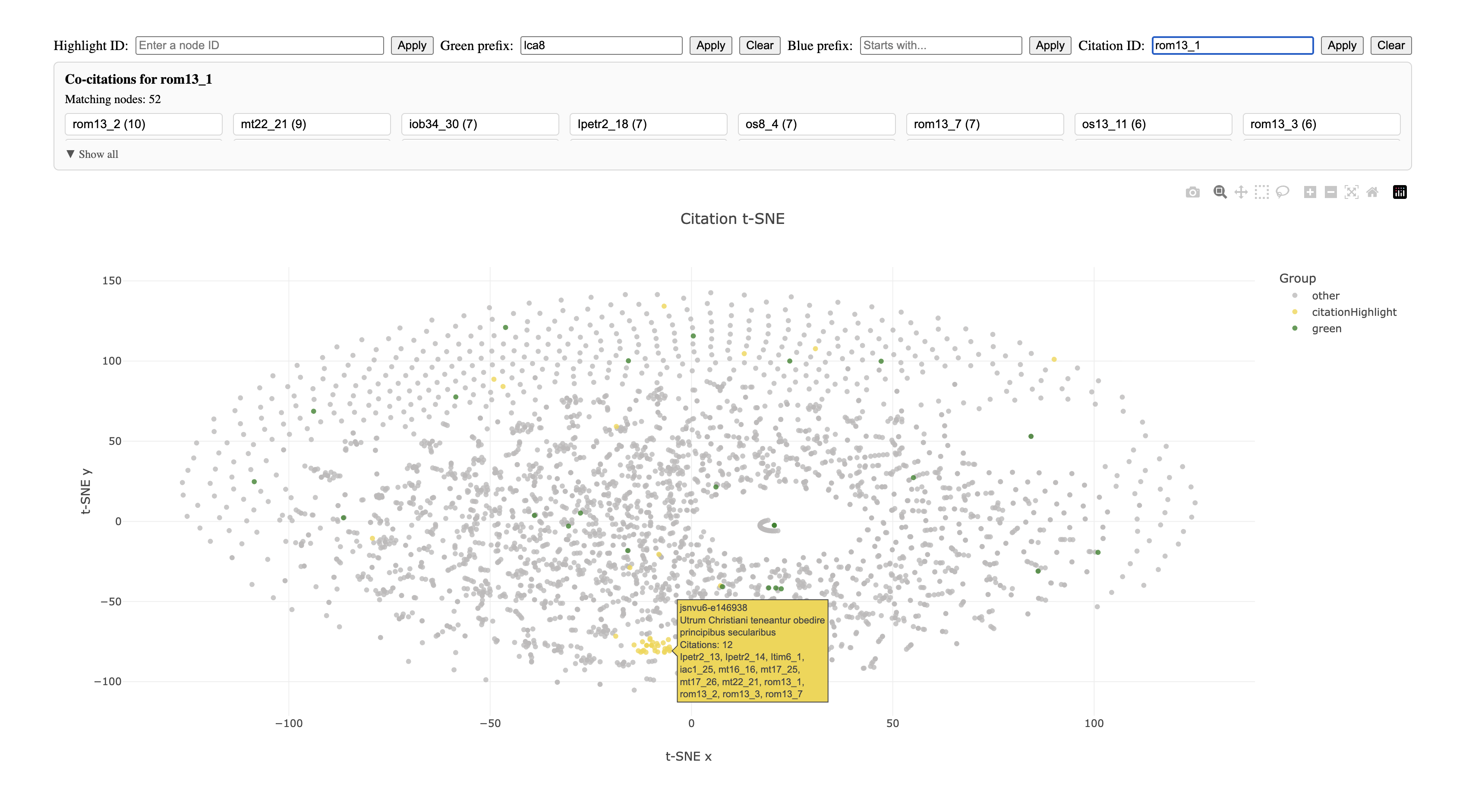
Immediately we can see most of the questions where these verses are used clustered because they also happen to cite other common verses. (We can also see which verses they frequently co-appear with.)
But we can also see some outliers, places where romans 13_1 is cited but none of other common verses are cited.
Both of these are interesting results.
- It shows us quickly what discussion a verse is most often called upon as an authority.
- And it also shows us surprising discussions where this verse is employed that we might not have otherwise expected it to be used.
If we can see and recognize the meaning of these clusters, then it only takes a little imagination to see how we might integrate these clusters into a reading environment.
We can imagine someone reading the text of Thomas Aquinas and asking for recommendations. In the side bar, they can get a list of recommendations based on similar patterns of biblical quotations. Included here we can see references to specific chapters of Las Casas (among many others).
As an added benefit, we suddenly find ourselves in a position (because all these scaffolded resources are in place) to make use of AI LLMs one more time.
Reading through this list of recommendations is useful, but what if we fed these recommendations into the context window of LLM.
Now we have an LLM that can do what a generic web chatbot cannot. Not only can the chatbot summarize and contextualize highly relevant sources, it can cite its sources and provide granular links to the source it has used. Now instead of giving us arbitrary connections or hallucinating non-existent sources, it has created a kind of annotated and transparent research pathway for us to explore.
This is similar to other kinds of highly productive and domain specific tools that we are starting to see in other fields like medicine.
Open Evidence is one such parallel example.

Open Evidence, like our new chatbot, is an example of a RAG (retrieval augmented generation). RAGs have the ability to retrieve and highlight relevant information for a given query and then provide transparent links back to the precise sources used to create the response.
Finally, in closing, I always like to stress that this computational dynamic approach does not come at the cost of traditional presentations.
Maybe you’re not interested in an LLM providing this kind of summary. What you really need is a traditional print outcome.
Does the approach I’m recommending come at the cost of this outcome, so that you are forced to choose?
Nothing could further from the truth. Even if our only goal is the traditional output, I would still argue that the traditional approach doesn’t scale. Because it is so time-consuming to create these indices, we get very few of them and they are often limited in their scope and nature, rather than tailored to our needs.
But with the approach I’m recommending these indices can be made at the touch of a button and because they can be made so quickly, we can generate them for all kinds of custom compilations.
Certainly, if I want to create an Opera Omnia of the works of Las Casas, I’ll want an index for his works.
One click and we have this.

But what if the recommendation list we’ve just seen has inspired me to offer a seminar on these clusters of related texts. I might want to order a “reader” for each student in my seminar that includes just these texts.
Well, I imagine traditional publishing cannot offer this. However, this can be generated immediately at no cost.
All I have to do is collect the recommended ids and, with the touch of a button, I have a new reader, with customized index for that specific compilation.



Conclusion
In sum…
- 1) I hope this has been helpful in showing some ways AI can be positively used in our field.
- 2) But a point I want to emphasize is that it only has this benefit because for the last decade I’ve been thinking about what it means to create historical editions within a completely different paradigm than the traditional publication model.
- C) If we put these two premises together, we have our conclusion:
- If we want to get real benefits from AI powered tools and not just vaporware or empty promises, then there is an urgent need for the field of scholarly editors to resist the workflows of traditional publishers and support a new publication workflow.
More concretely, if you are ever interested in working on a new edition or part of an edition from the scholastic tradition broadly conceived, medieval or modern, consider emailing me and consider working with me as a new kind of open access publisher.
Likewise, if you’re engaged in a project tracing biblical, patristic, or canon law reception, please contact me. I can show you how to use to current index. And if your text of interest is not yet published as machine actionable data, let me know and I can put it on my priority list.
If you’re intrigued by using AI agents to encode quotations, take a look at how I’m experimenting with it to do other editorial tasks, such as:
correcting transcription errors
or recording and annotating variants