SCTA und Topic Modelling: ein DAAD Bericht
SCTA und Topic Modelling: ein DAAD Bericht
Mit der Explosion von Daten wird die Frage der Zukunft nicht sein, “Ist dieser Text oder sind diese Daten verfügbar?”, sondern “Können wir diesen Text oder Text-Teil finden in dem Stapel dessen, was verfügbar ist?”
Die wissenschaftliche Gemeinde lagert diese Aufgabe der adäquaten Auswahl von Informationen auf eigene Gefahr aus. Wenn Daten theoretisch verfügbar sind, aber noch nicht auffindbar, dann ist dies ein Problem von Kuration. Wenn wir tausende oder sogar Millionen Ergebnisse haben, können wir nicht alle diese Ergebnisse untersuchen. Wir müssen auswählen und das ist Kuration. Kuration ist eine Art von Auswahl beruhend auf Grundsätzen. Wissenschaftliche Entdeckung fordert Kuration beruhend auf wissenschaftlichen Grundsätzen. Diese Kuration auszulagern und zum Beispiel Google zu überlassen, heißt, mit unwissenschaftlichen Ergebnissen zu arbeiten. Wir, die Fachleute, müssen die Verantwortung wieder übernehmen, die neuen digitalen Ansätze zu lernen und anzuwenden, so dass wir in der Lage sind, an der Aufgabe von Kuration teilzunehmen.
Mithilfe des Deutschen Akademischen Austausch-Dienstes habe ich als Leiter des SCTA (Scholastic Commentaries and Texts Archive, https://scta.info) einen ersten Schritt in diese Richtung gemacht, einen ersten Versuch, diese Verantwortung zu übernehmen.
Anfang Oktober 2018 habe ich mit meinem Kollegen Dr. Thomas Köntges bei der Digital Humanities Lab an der Universität Leipzig versucht, einen Ansatz des “Natural Language Processing” Ansätze, nämlich das sogenannte “Topic Modelling”, auf das SCTA Korpus anzuwenden.
Die Grundidee ist, dass wir mit der Kombination von Computer-Rechenleistung und Fachkenntnis ein Profil jedes Absatzes im Scholastik-Korpus bauen können. Mit diesen Profilen können wir erwartete und unerwartete Verbindungen im gesamten Korpus entdecken.
Nichts von dem wäre möglich gewesen ohne die Fachkenntnis und Zusammenarbeit mit Dr. Thomas Köntges. Dr. Köntges hat eine wichtige Applikation entwickelt, die “ToPan” heißt und mit der man Texte analysieren und “Topics” erschaffen kann.
In dem Bild unten kann man ein Beispiel eines Topics sehen, das von Dr. Köntges Applikation “ToPan” erzeugt wurde.
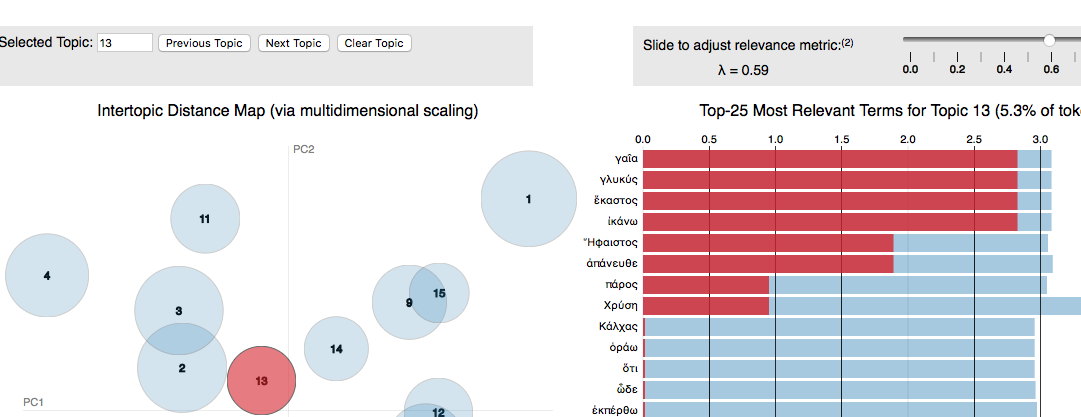
Mit diesen Topics oder Themen kann man dann dieses Korpus unterscheiden und sortieren.
Die Frage ist nur: Wie kann man ein so riesiges Korpus wie das SCTA Korpus automatisch in diese Applikation eingeben? Um das zu schaffen, habe ich ein “CSV API” für das ganze SCTA-Korpus erzeugt. Dieses API macht Millionen von Lateinischen Wörtern, die in scholastischen Texten gefunden werden, in einer Form verfügbar, die eine Applikation wie “ToPan” verstehen kann.
Der nächste Schritt, bevor diese Ergebnisse nützlich sein werden, ist diese Ergebnisse in solcher Weise zu veröffentlichen, dass sie von anderer “Client Applications” gebraucht werden können. Dr. Köntges hat schon eine weitere Applikation entwickelt, die Metallo heißt, um diese Ergebnisse darzustellen. Zusammen haben wir diese Applikation modifiziert, so dass sie die Ergebnisse als nützliche Daten verfügbar machen kann, nämlich als “JSON data”.
Nach diesen Schritten waren wir jetzt in der Lage, diese Ergebnisse zu benutzen, um unseren Text und Suchdienst zu verbessern.
Die offensichtlichste Anwendung von diesen Absatz-Profilen ist, Nutzern zu erlauben, Suchergebnisse nach Themen zu gliedern und zu sortieren. Auf diese Art und Weise vermeiden wir unwissenschaftlichen Gebrauch von Suchergebnissen, worin wir nur die ersten Suchergebnisse wählen, weil sie zuerst vorkommen, und nicht, weil sie die besten sind oder (sie) am Besten zu unserer Forschung passen.
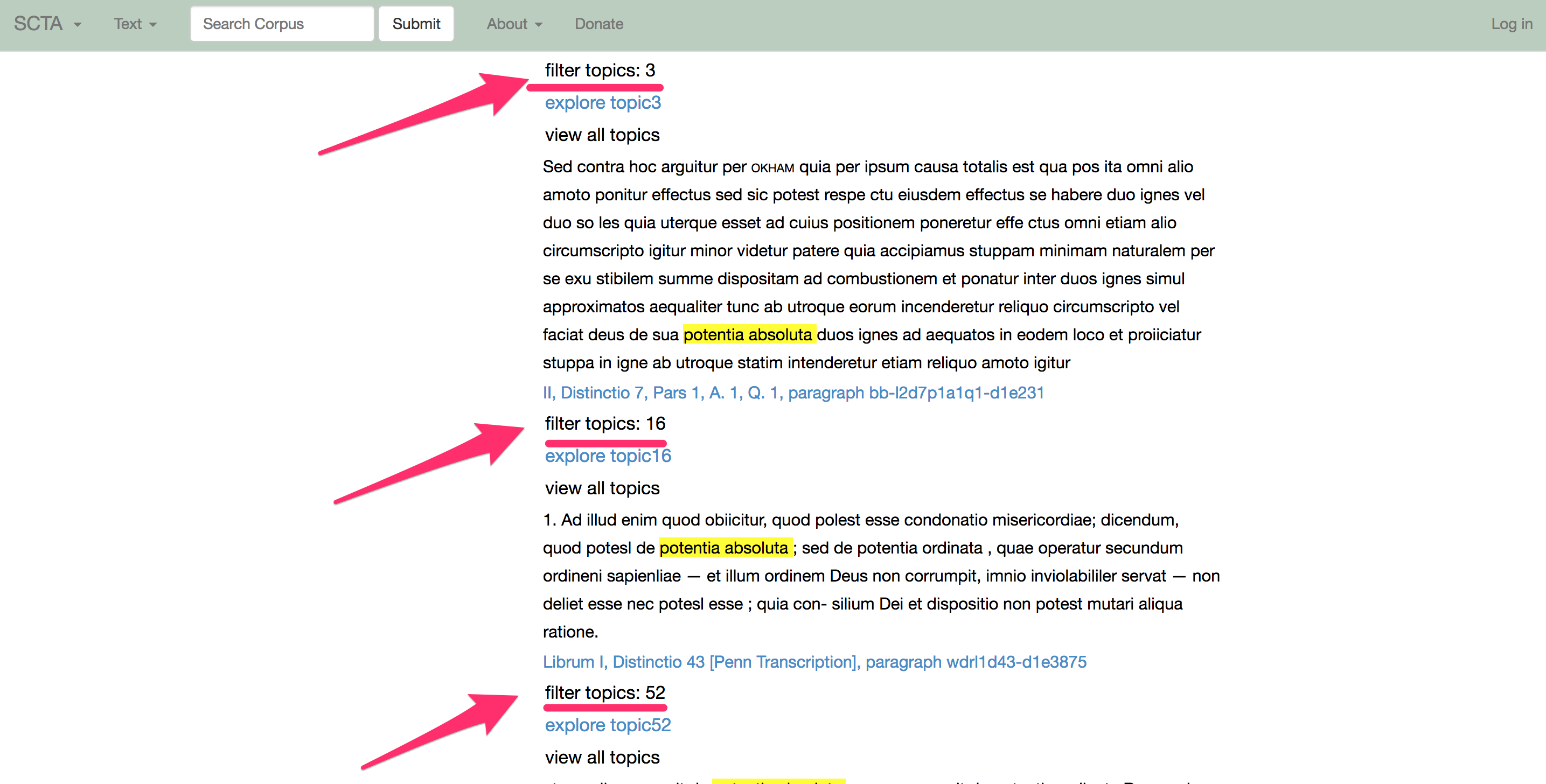
Zum Beispiel kann man in dem ersten Bild unten eine Liste von unsortierten Suchergebnissen sehen. Der Suchdienst hat das Ergebnis “potentia absoluta” in vielen verschiedenen Absätzen gefunden, aber das Absatz-Profil und ein verbundenes Thema weisen darauf hin, dass die folgenden Absätze dieselbe Phrase, “potentia absoluta”, in drei verschiedenen Diskussionen benutzen.
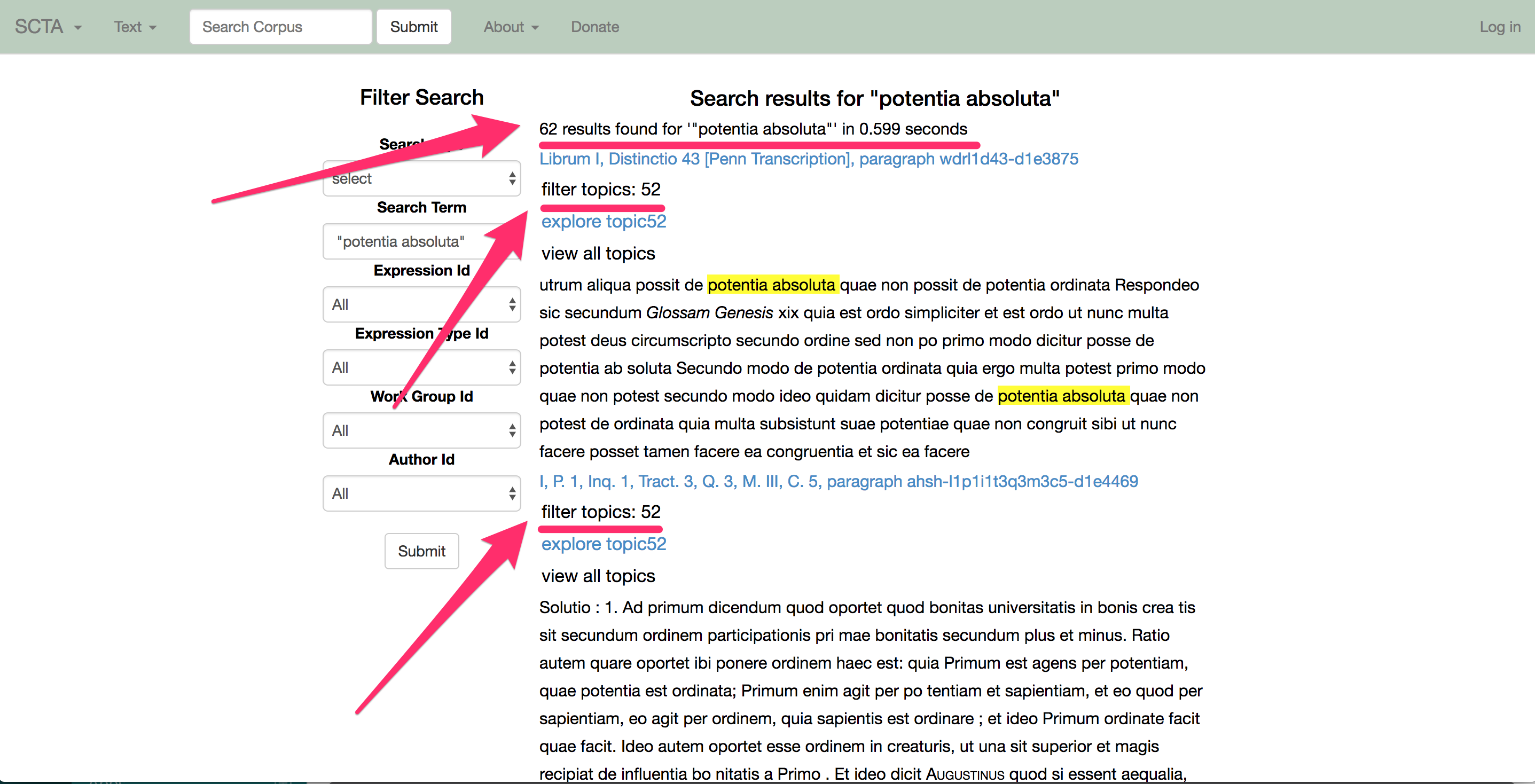
Ein einfaches Beispiel wäre: eine rohe Suche für das Wort “Leiter”, die Absätze zurücksendet, die sowohl etwas mit einem Bergsteiger als auch mit einem Chef von einem Geschäft zu tun haben. Mithilfe von Topic Modelling können wir diese verschiedenen Diskussionen sortieren, wie man in dem zweiten Bild sehen kann.
Hier kann ein Nutzer ein Topic auswählen und nur die Absätze sehen, die etwas mit dieser Diskussion zu tun haben.
Aber die Sortierung von Suchergebnissen ist nur der Anfang.
Mithilfe von einem Profil für jeden Absatz zielen wir darauf, einen Empfehlungsdienst zu bauen. Solch ein Dienst sollte einen traditionellen Anspruch erfüllen, nämlich, die Fähigkeit Nutzer zu verknüpfte Diskussionen zu führen.
In diesem Bild können wir sehen, dass das ein traditionelles Ziel ist.
Cremona 1618 https://books.google.com/books?id=h2IUiZ6aYZUC&pg=PA66#v=onepage&q&f=false

Viele weitere Beispiele aus dem 16. und 17. Jahrhundert könnten gefunden werden.
Aber dieser Anspruch hat sogar bis in die moderne Zeit angehalten.
Das Skolion der Ausgabe von Bonaventure aus dem späten 19. Jahrhundert ist ein treffliches Beispiel.

Diese Arten von Verbindungen sind wichtig. Sie machen uns den größeren Zusammenhang bewusst. Einige Verbindungen könnte ein Fachmann / eine Fachfrau vorhersehen. Wir können erwarten, dass ein Kommentar zu Distinctio 17 sich auf viele andere Kommentare zu Distinctio 17 beziehen kann.
Aber unsere Erwartungen sind auch unsere Grenze, denn wir suchen Verbindungen nur dort, wo wir diese erwarten. Und offensichtlich bleiben uns jene Verbindungen verborgen, die wir nicht erwarten.
Die Hilfe, hier von wohlmeinenden Herausgebern zur Verfügung gestellt, gibt uns nur ein Muster von Verbindungen. Diese ist jedoch keineswegs umfassend oder wissenschaftlich. Sie ist nur eine Auswahl, die auf den Vorlieben des Herausgebers beruht. Und obwohl diese Auswahlen oft hilfreich sein könnten, steuern sie trotzdem die Richtung aller nachfolgenden Forschung, entgegen jeder Forderung von Wissenschaft oder historischer Genauigkeit. Ist der Verweis in der Bonaventura Skolion auf die parallele Diskussion in Gregory Biel nur da, weil diese in Biel eng verbunden mit jener in Bonaventure ist? Enger oder wichtiger als alle Diskussionen, die zwischen der Zeit Bonaventures und der Zeit Biels (fast zweihundert Jahre) stattgefunden haben, die trotzdem nicht erwähnt sind? Es ist wahrscheinlicher, dass Biel im Kopf des Herausgebers einer der “Big Guys”, einer der “wichtigen Scholastiker,” ist und deshalb ist ihm diese Diskussion bewusst. Dieser Prozess allerdings ist ein Teufelskreis. Biel ist gelistet, während viele andere spätere Scholastiker nicht gelistet sind, weil der Herausgeber glaubt, dass Biel wichtiger ist. Nachforscher sehen diese Liste und orientieren ihre Arbeit daran. Aufgrund der begrenzten Zeit entscheiden sich die nachfolgenden Forscher von diesem Skolion, die Diskussion von Biel zu untersuchen und übersehen die anderen Diskussionen. Also geht der Kreis weiter und unweigerlich entdecken wir nur, was unsere bisherigen Entscheidungen uns erlauben zu entdecken.
Was wir brauchen, ist ein wissenschaftlicherer und umfassenderer Ansatz: ein Ansatz, der die Diskussionen enthüllt, die von unseren Vorurteilen versteckt werden.
“Topic Modelling” kann uns hier helfen. Mit der Hilfe gewaltiger Computerrechenleistung können wir die Relevanz jedes Absatzes betrachten; nicht nur die Absätze, die uns schon bekannt sind. Der Computer kann ein Profil von jedem Absatz bauen und wir können dieses Profil benutzen, um verbundenen Passagen zu empfehlen und anzuzeigen.
Während meiner Zeit in Leipzig habe ich mit Dr. Köntges ein Beispiel entworfen, um diese Möglichkeiten zu demonstrieren.
Unten kann man sehen, was passiert, wenn man nach mehr Information über diesen Absatz fragt. Zunächst bekommt man eine Liste von Absätzen mit einer direkten Verbindung zum entsprechenden Absatz. Diese Verbindungen sind die gefundenen Ergebnisse eines Forschers. z.B. dieser Absatz zitiert den Anderen und so weiter.
Aber unten ist eine neue Liste von verbundenen Absätzen, dessen Verbindungen von Computer bestimmt wurden. Und in diesem Fall hat der Computer das ganze Korpus analysiert und deshalb kann er Passagen empfehlen, die jenseits der Vorurteile des Herausgebers bestehen.
Und abermals, in demselben Bild können wir diese in Beziehung stehende Absätze in einer graphischen Darstellung.

In der Zukunft planen wir beide Ansätze immer enger zusammenzubringen, so dass wir durch die Kombination von Eigenschaften, die von den Forschern erzeugt wurden, und jenen, die vom Computer erzeugt wurden, einen effektiven Empfehlungsdienst erschaffen können: einen Dienst, der uns erlaubt, die Verbindungen den ganzen Korpus hindurch in einer wissenschaftlichen und umfassenden Weise zu sehen.