Einleitung
Ich war einmal in Münster, um einen Vortrag über mein Text-Archiv zu halten. In diesem Vortrag habe ich versucht zu erklären, warum es so wichtig ist, unsere kritischen Editionen historischer Texte als “Machine Accessible Daten” vorzubereiten und nicht nur als ein gedrucktes Buch. Und danach hat mich jemand sehr direkt gefragt. “Lohnt es sich”?
Mit dieser Frage habe ich verstanden, dass der Mann die neuen editorischen Prozesse (die ich empfohlen hatte) als schwieriger als “den normalen Prozess” empfunden hatte. Und er fragte sich, “was bekomme ich dafür, wenn ich diesen neuen Prozess übernehme?”
Zuerst einmal bin ich nicht der Meinung, dass es wirklich einen so-genannten “normalen Prozess” gibt. Was normal heißt, ist nur ein Prozess, an den wir so gewöhnt sind, dass wir ihn als einfach und mühelos sehen, und darum vergessen wir, dass wir diesen Prozess irgendwann gelernt haben.
Aber ich nehme den Einwurf an. Er konnte keinen Grund sehen, warum er eine neue Normalität aufbauen sollte.
Für mich waren die zukünftigen Möglichkeiten “at Scale” ganz klar, aber diese Möglichkeiten sind schwierig zu demonstrieren, wenn wir noch nicht “at Scale” sind. Aber wir können nicht zu Scale kommen, wenn Leute diese Möglichkeiten nicht sehen und uns daher nicht helfen, diese “Scale” zu erreichen. Am Anfang befinden wir uns also in einem kleinen Teufelskreis.
Um diesem Teufelskreis zu entkommen, braucht man Geduld. Wir müssen geduldig Daten hinzufügen, bis wir einen Umfang erreichen, der groß genug ist, um die Möglichkeiten der Skalierbarkeit zeigen zu können.
Ich stehe noch am Anfang von diesem Prozess, aber ich glaube, dass ich langsam einen Umfang erreiche, bei dem ich einige Möglichkeiten realisieren und konkret zeigen kann.
Deshalb hoffe ich, heute anhand von einigen Beispielen zeigen zu können, wie die Übernahme von besserer editorischer Praxis (at Scale) auch bei traditionellen Zielen zu besseren Ergebnissen führt.
Dabei will ich in einer semi-autobiographischen Form vorgehen und eine kleine Geschichte von meinen verschiedenen Versuchen erzählen, Quellen und deren unterschiedliche Einflüsse (innerhalb eines großen Korpus) zu entdecken. Diese Geschichte führt mich zu den aktuellen Prozessen, die ich jetzt benutze und mit denen ich weiter experimentiere. Und obwohl ich die Experimente fortsetze, glaube ich, dass ich schon ein paar Beispiele von echten Entdeckungen aufzeigen kann, die Antworten auf traditionelle Fragen beinhalten. Auf diese Weise würde sich die anfängliche Frage, ob sich das denn alles lohnt, von selbst beantworten.
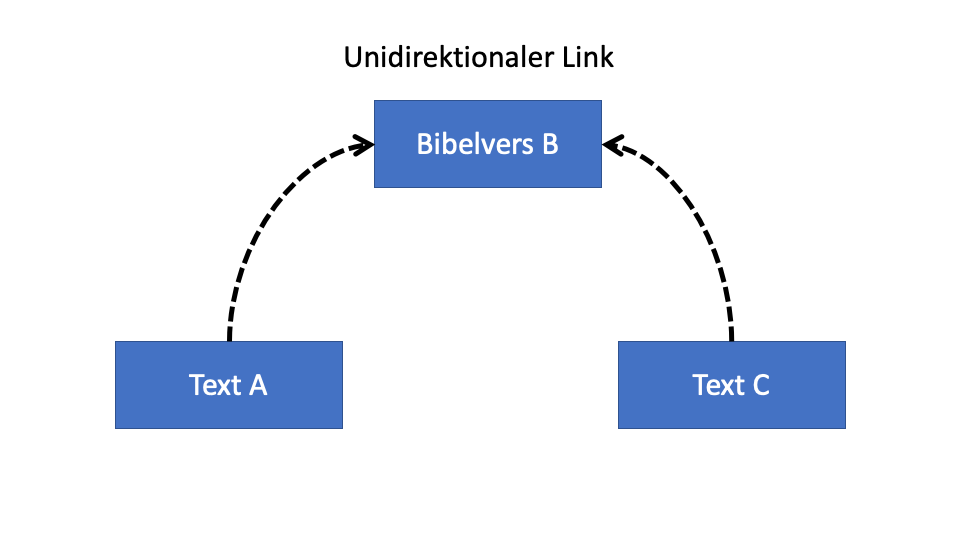
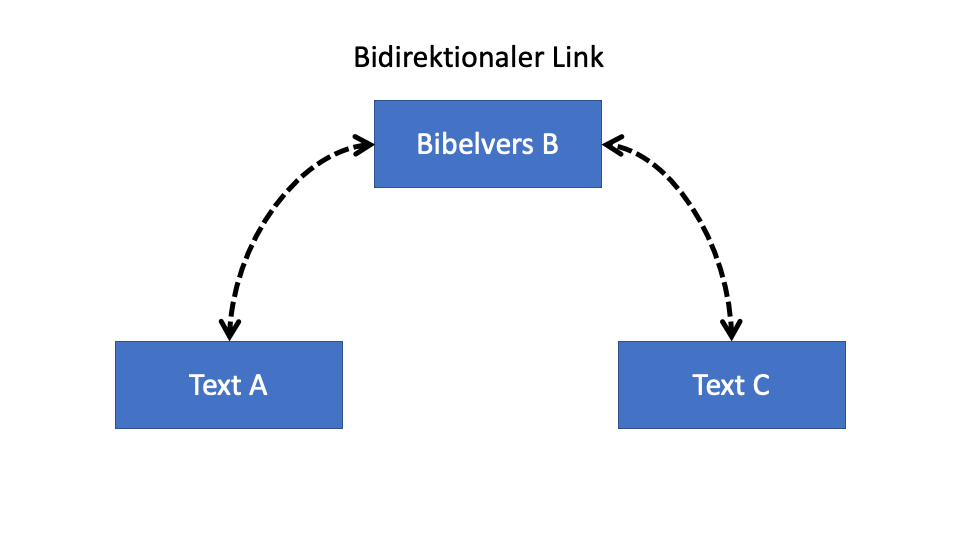
Aspiration für Zitatsnetwork mit dem traditionellen Apparatus Fontium
Am Anfang wollte ich von der editorischen Arbeit profitieren, die Editoren sowieso schon tun.
Im traditionellen Workflow, wo man eine Quelle entdeckt, speichert man diese Daten in einer Fußnote ganz unten auf der Seite.
Das bedeutet: wenn jemand ein Zitat von De Trinitate von Augustinus in einem anderen Text (z.B. eines Autors aus dem 14ten. Jahrhundert) gefunden hat und das unten auf der Seite in einer Edition geschrieben hat, bemerkt niemand (der De Trinitate von Augustinus liest) diese Verbindung, solange es keine aktualisierte Ausgabe gibt.
Um die Verbindung zu Augustinus zu entdecken, muss man nicht nur den Autor in der Zukunft kennen, sondern auch diese spezifische Edition. Und das gilt in meinem Beispiel nur für einen Autor. Um den Einfluss “at Scale” sehen zu können, müssen wir diese Schritte für jeden zukünftigen Autor wiederholen. Das erfordert zu viel.
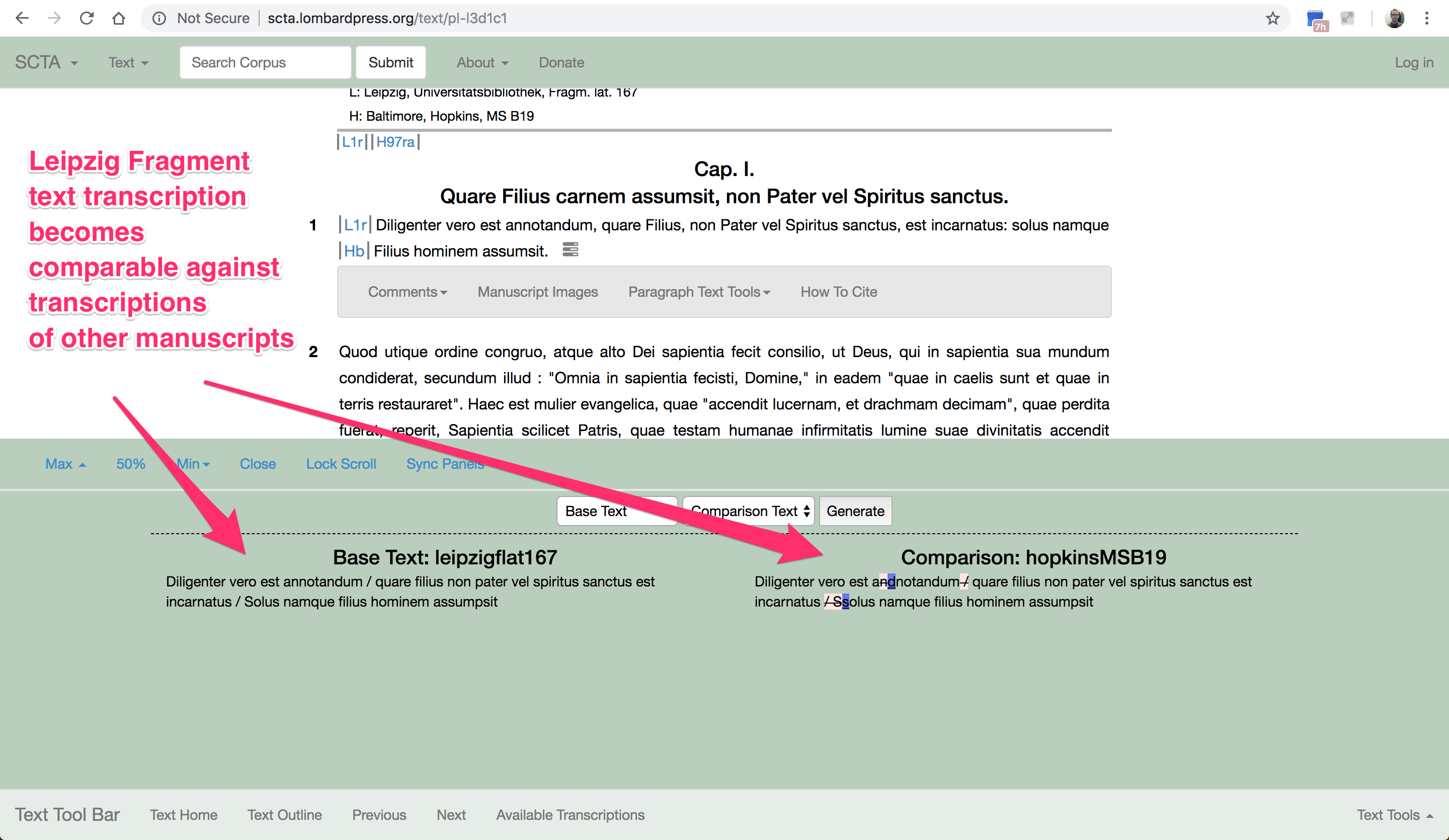
Wenn wir aber unsere editorische Praxis wechseln, indem wir unsere Fußnoten mit “Machine Actionable Data Links” statt Text machen, dann können wir die Arbeit von verteilten Editoren automatisch sammeln und folglich diesen Einfluss “at Scale” sehen.
Ein paar Beispiele:
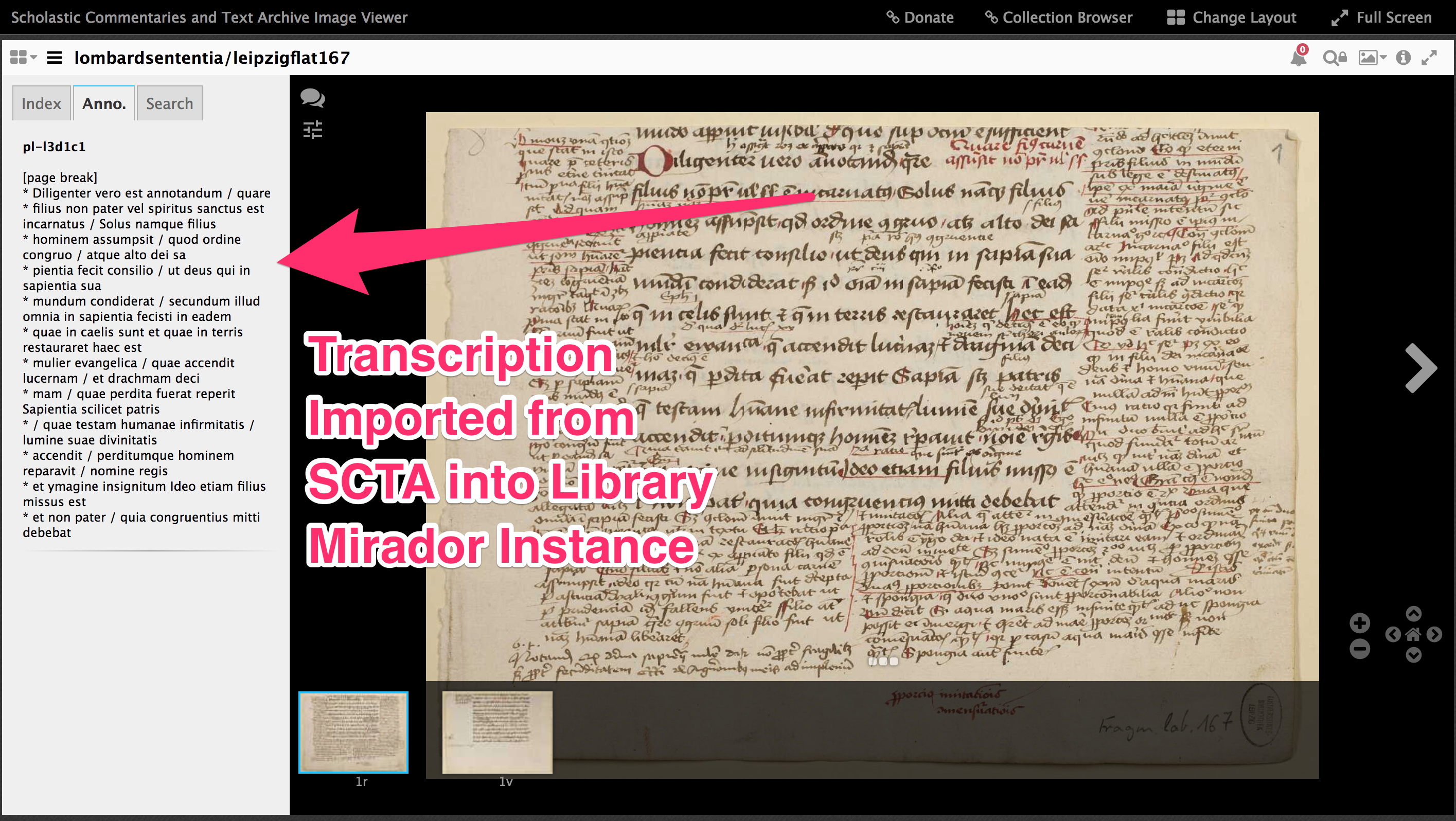
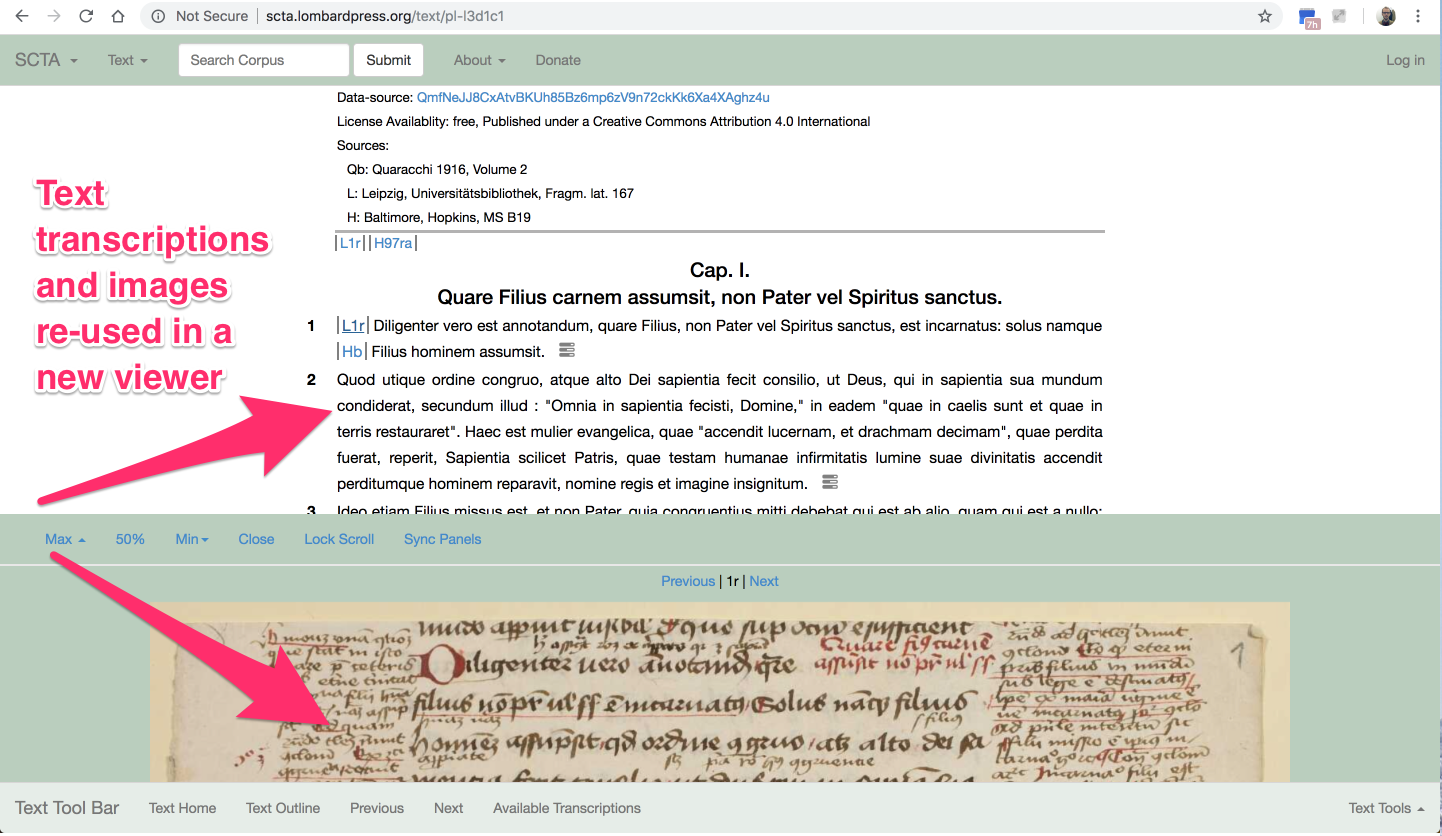
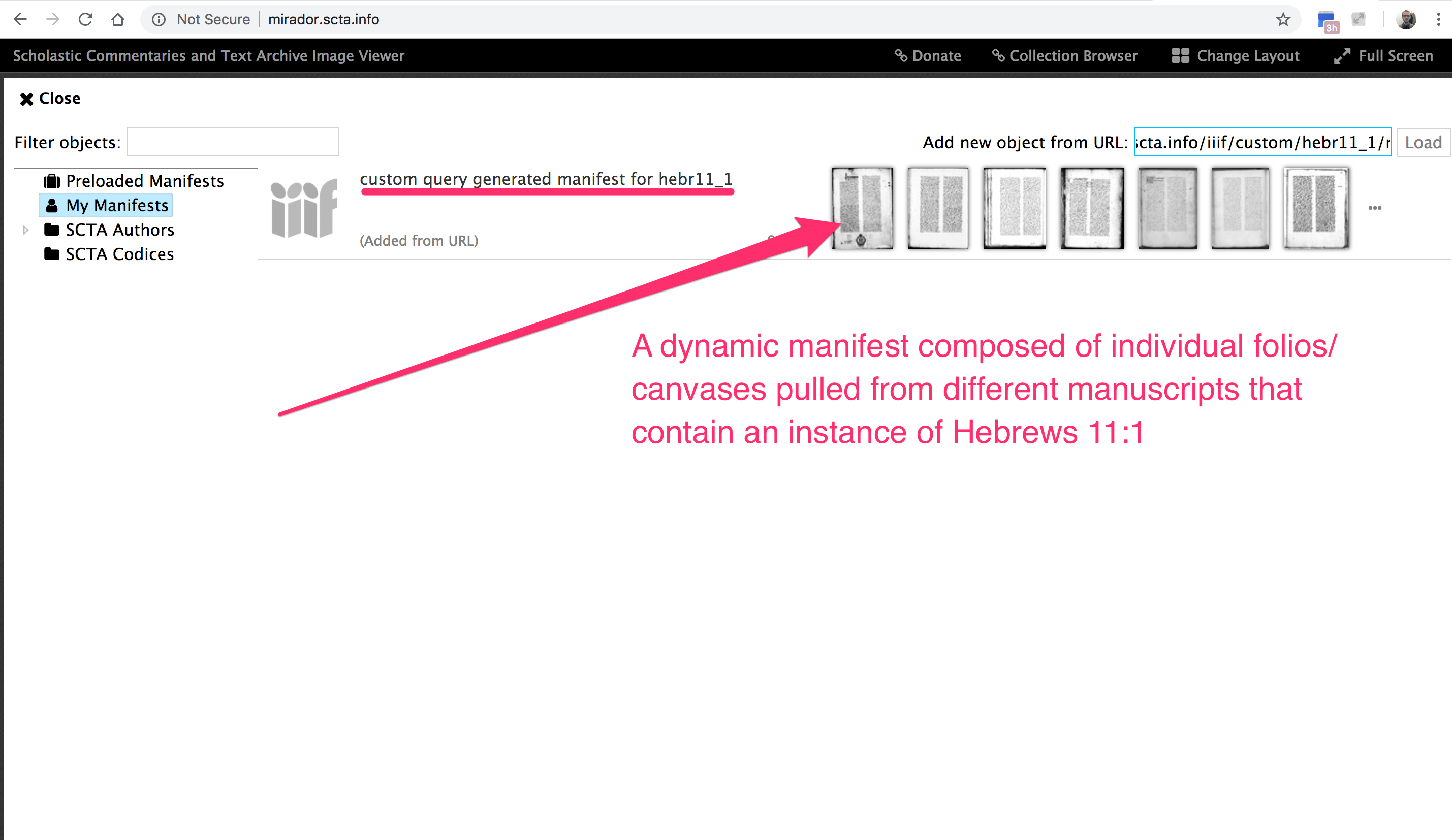
Hier fokussiert man auf eine Target Passage und unmittelbar bekommt man eine Liste (auf der linke Seite) von allen künftigen Passagen, die die Target Passage zitieren.
Bild 1

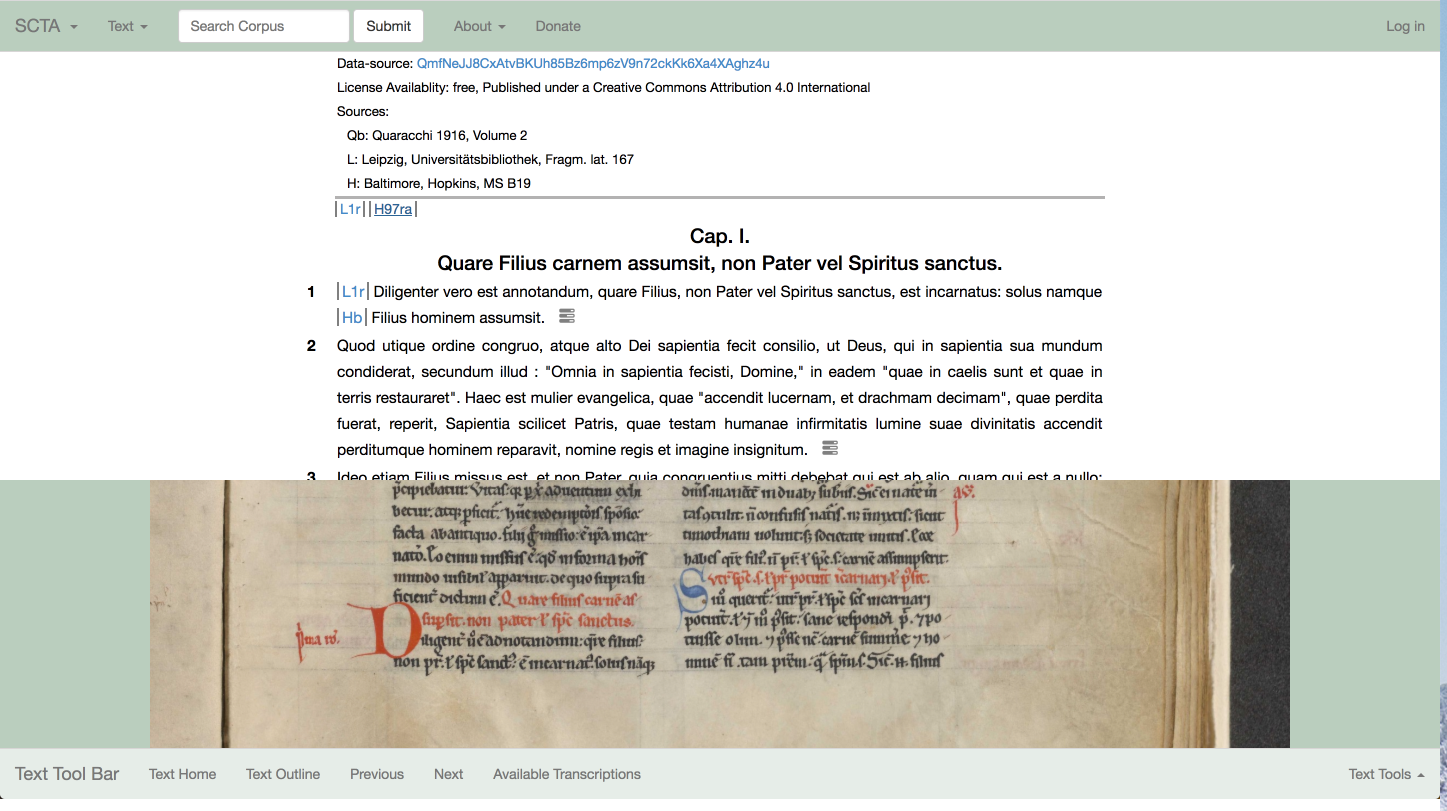
Und hier ist dieselbe Information aus einer anderen Perspektive:
Bild 2

Schon mit diesem relativ einfachen Ansatz, können wir in Kombination mit Korpus-Metadaten, große Muster erkennen.
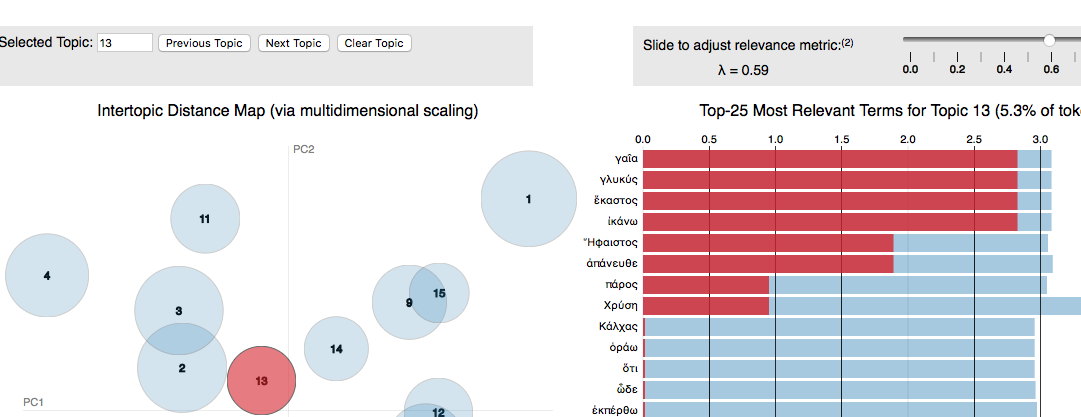
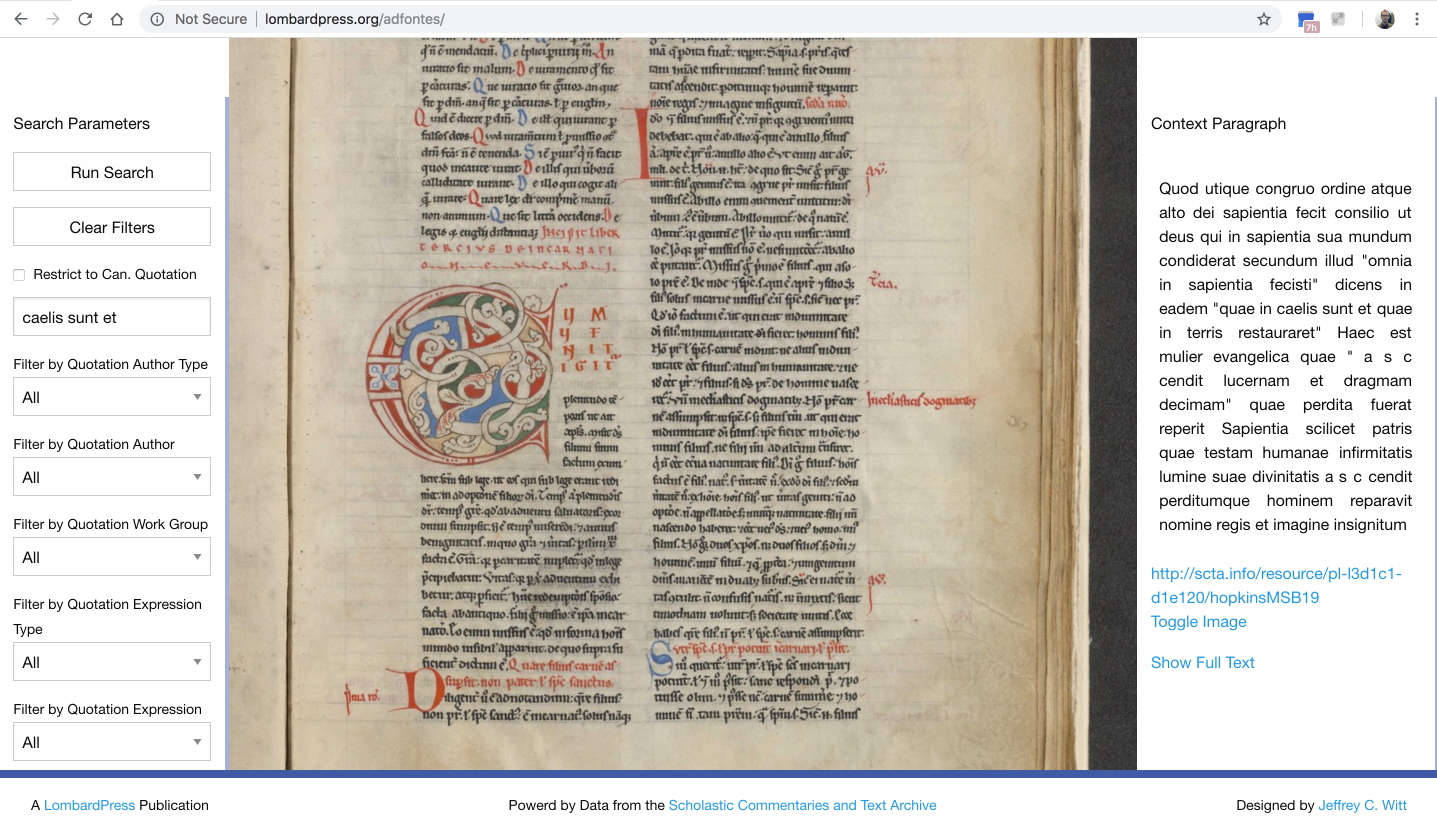
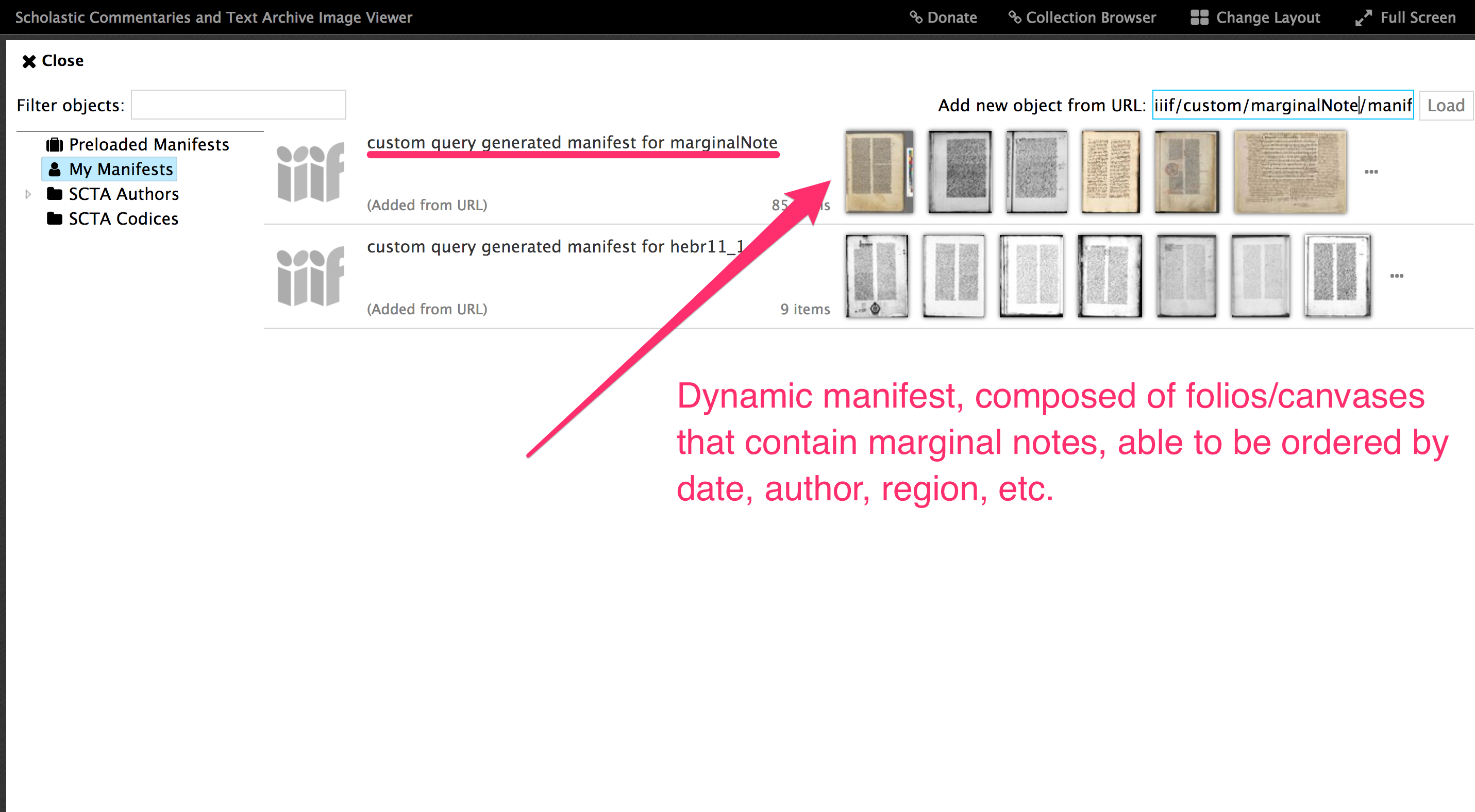
Hier, auf dem nächsten Bild (Bild 3), habe ich alle Zitate von Bibelversen in separaten Bibel-Abschnitten gezählt, die in Prologen von “Sentenzen Kommentaren” erscheinen.
Wir können zum Beispiel sehen, dass bestimmte Verse von den Psalmen in Prologus von Petrus Lombardus nicht erscheinen.
Aber plötzlich in Aquinas sehen wir die Nutzung von diesen Versen, und danach die Fortsetzung dieser Nutzung. Diese Fortsetzung der Nutzung könnte den Einfluss von Aquinas auf die folgende Tradition zeigen.
Bild 3

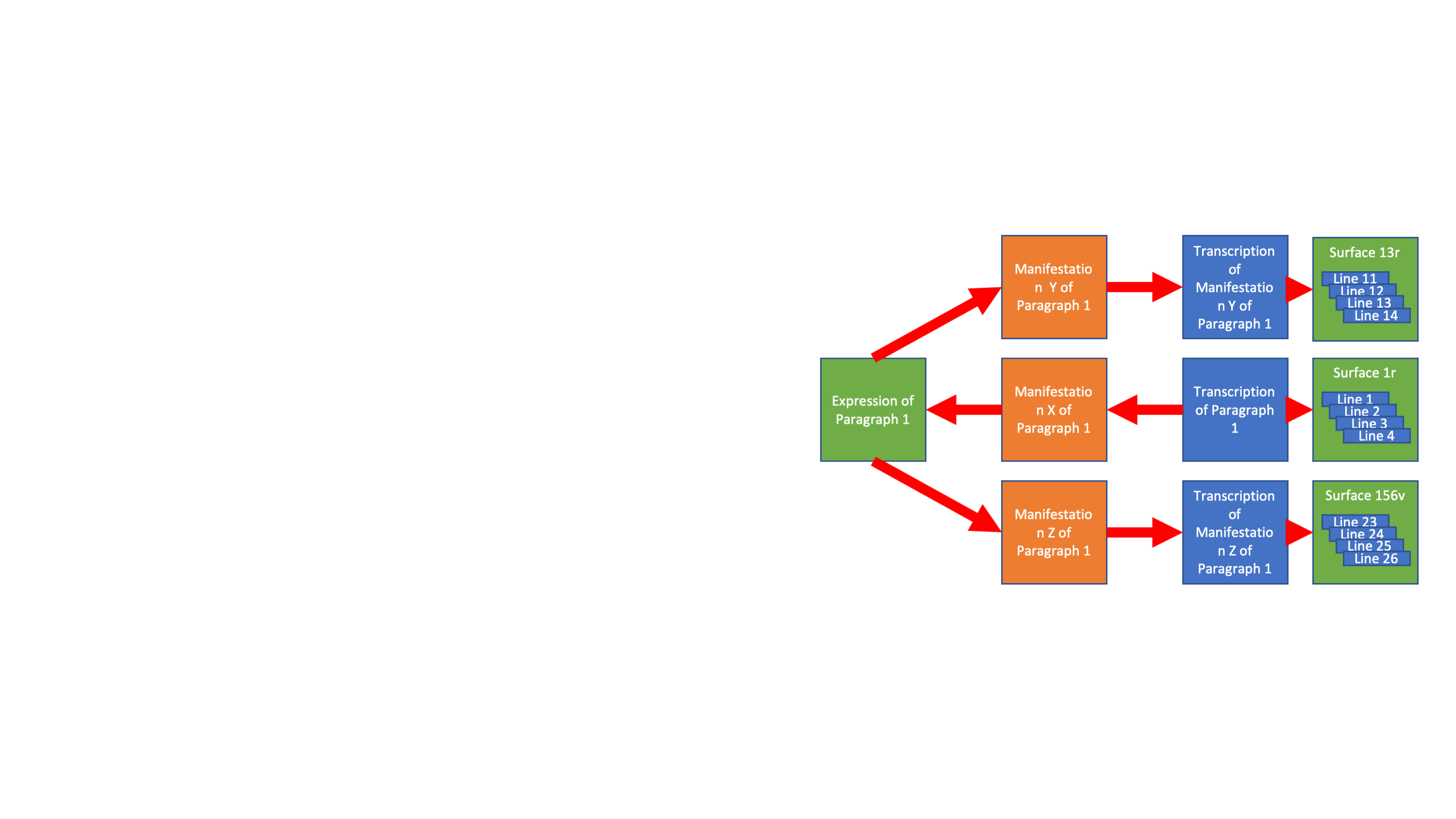
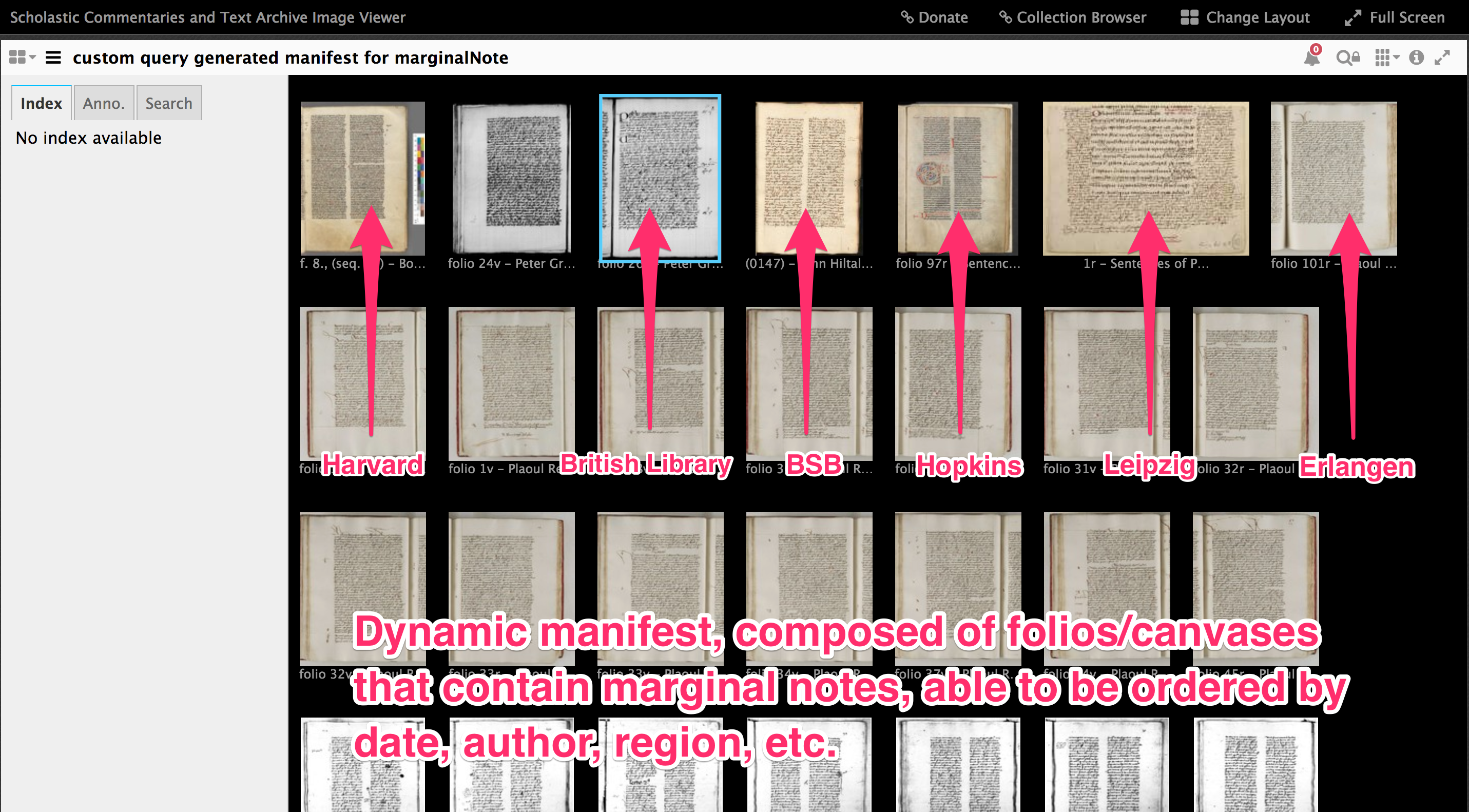
Es ist hier wahrscheinlich hilfreich (ganz Kurz), etwas über die Natur eines Sentenzenkommentars zu sagen, und wie man diese Kommentare studiert.
Das Buch von Petrus Lombard (das “die Sentenzen” heißt) wurde im 12ten Jahrhundert geschrieben und umfasst (insgesamt) 4 Bücher. Jedes Buch hat ein Thema (Gott, die Schöpfung, Christus, die Kirche). Jedes Buch wird in verschiedene Distinctiones (auch mit einem Prologus) gegliedert. Und jede Prologus und Distinctio hat sein eigenes Thema.
Bild 4

Diese Tradition ist so wichtig, weil nach Lombard, so viele Leute Kommentare an jeder Distinctio geschrieben haben. Ungefähr 1600 über 5 Jahrhunderte.
Bild 5

In Bezug auf die Begriffsgeschichte ist diese Tradition eine Goldmine, weil wir eine kontinuierliche Diskussion über ein sehr spezifisches Thema haben. Wenn wir den richtigen Zugang und die richtigen Werkzeuge haben, können wir beobachten, wie viele Begriffe über die Zeit sich ändern. Um den Zugang zu einem so großen und komplexen Korpus zu erleichtern, arbeiten wir u.a. ( unter anderem) mit folgenden Perspektiven:
Bild 6
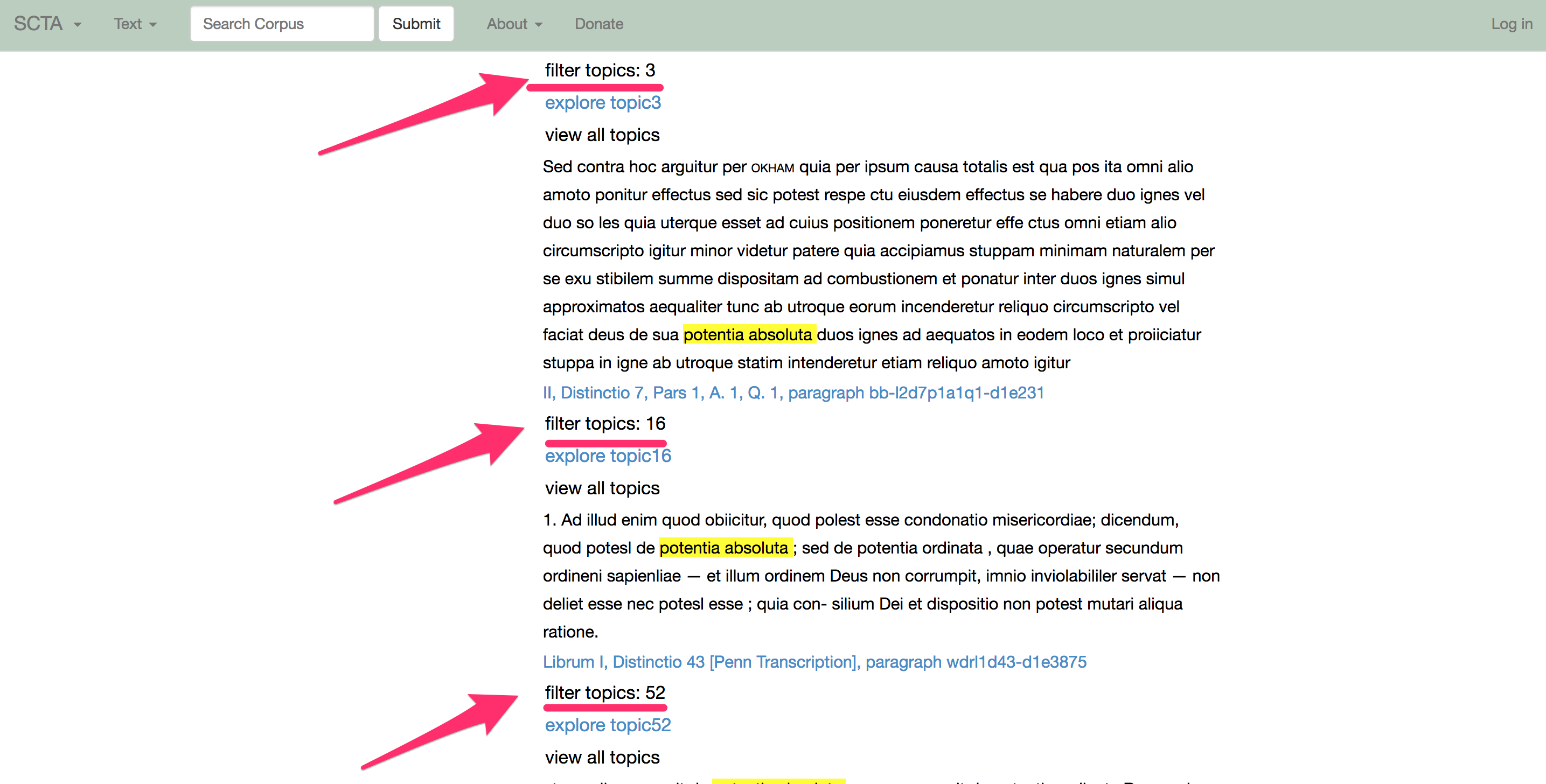
Dieser Ansatz (Bild 6) hat definitiv Potenzial. Allerdings sind die Daten hier noch unvollständig, weil sie davon abhängig sind, dass die Zitate und Verweise von einem Editor manuell erkannt und markiert werden.
Bild 7

Das erfordert eine Menge Mühe und die volle Teilnahme der editorischen Community. Solche Teilnahme haben wir noch nicht.
In einer Community mit wenigen wahren Anhängern und mit noch weniger Beitragenden, ist der Fortschritt langsam und echte Entdeckungen sind rar.
Denn im Moment verhindert diese Unvollständigkeit nützliche Interpretationen, darum bleiben wir leider meistens (wie wir oben gesehen haben) im Reich von Möglichkeiten.
Entdeckung der Ähnlichkeit mit N-Grams
Weil ich meistens allein arbeite, habe ich erkannt, dass ich andere Ansätze für die Textähnlichkeit-Erkennung ausprobieren muss.
Die Nutzung von N-Grams ist technisch ziemlich einfach, aber ich war überrascht von ihren Möglichkeiten, besonders wenn diese Ngrams mit Metadaten vom Korpus Graph kombiniert werden.
Die Methode funktioniert wie folgt.
Um einen Korpus mit rund 80 Millionen Wörtern zu analysieren, habe ich ein kleines Programm geschrieben, das durch jeden Absatz läuft und jedes einzigartige 4-Gram speichert.
z.B.
“Die Katze ist auf der Matte” hat drei 4-grams
- Die Katze ist auf
- Katze ist auf der
- ist auf der Matte
Jedes 4-Gram wird eine Ressource in einem Graph und verwendet eine Relation/Property, die “sctap:isFoundIn” heißt und diese Property deutet auf jeden Absatz hin, der dieses N-gram enthält.
In “description” Logik, haben wir die Folgende: “Ngram.isFoundIn.Paragraph”
z.B.
Sctar:videturquodnonsic sctap:isFoundIn sctar:para1; sctar:para5; sctar:para10; sctar:para21 .
Grundsätzlich haben wir ein einfaches Wörterbuch (“Dictionary”) gebaut, mit dem man ganz schnell ein N-gram benutzen kann, um jeden Absatz zu finden, der dieses N-gram enthält.
Aber was wir wollen, ist die Ähnlichkeit zwischen Absätzen. Also was wir hier brauchen ist eine Definition von “Ähnlichkeit” oder eine entsprechende Interpretation durch den Datengraph.
In diesem Experiment habe ich selbst vordefiniert: zwei Absätze sind “ähnlich”, wenn sie 6 oder mehr 4-Grams gemeinsam teilen. Anders gesagt, sie sind ähnlich, wenn die “Intersection” von 4-Grams größer ist als 6.

Oder
X is related to Y, if and only if
\(\#\{ a | \forall{n}\forall{x}\forall{y}(IsFoundIn(n,x) \land IsFoundIn(n,y) \land x \neq y \} >= 6\)
Diese Interpretation könnte, übersetzt in eine SPARQL Abfrage, so aussehen:
SELECT (COUNT(*) as ?count) ?start ?target
WHERE {
?ngram <http://scta.info/property/isFoundIn> ?start .
?ngram <http://scta.info/property/isFoundIn> ?target .
FILTER(?start != ?target) .
}
GROUP BY ?start ?target
HAVING (?count >= 6)
N-gram Visualisierung: Erster Versuch
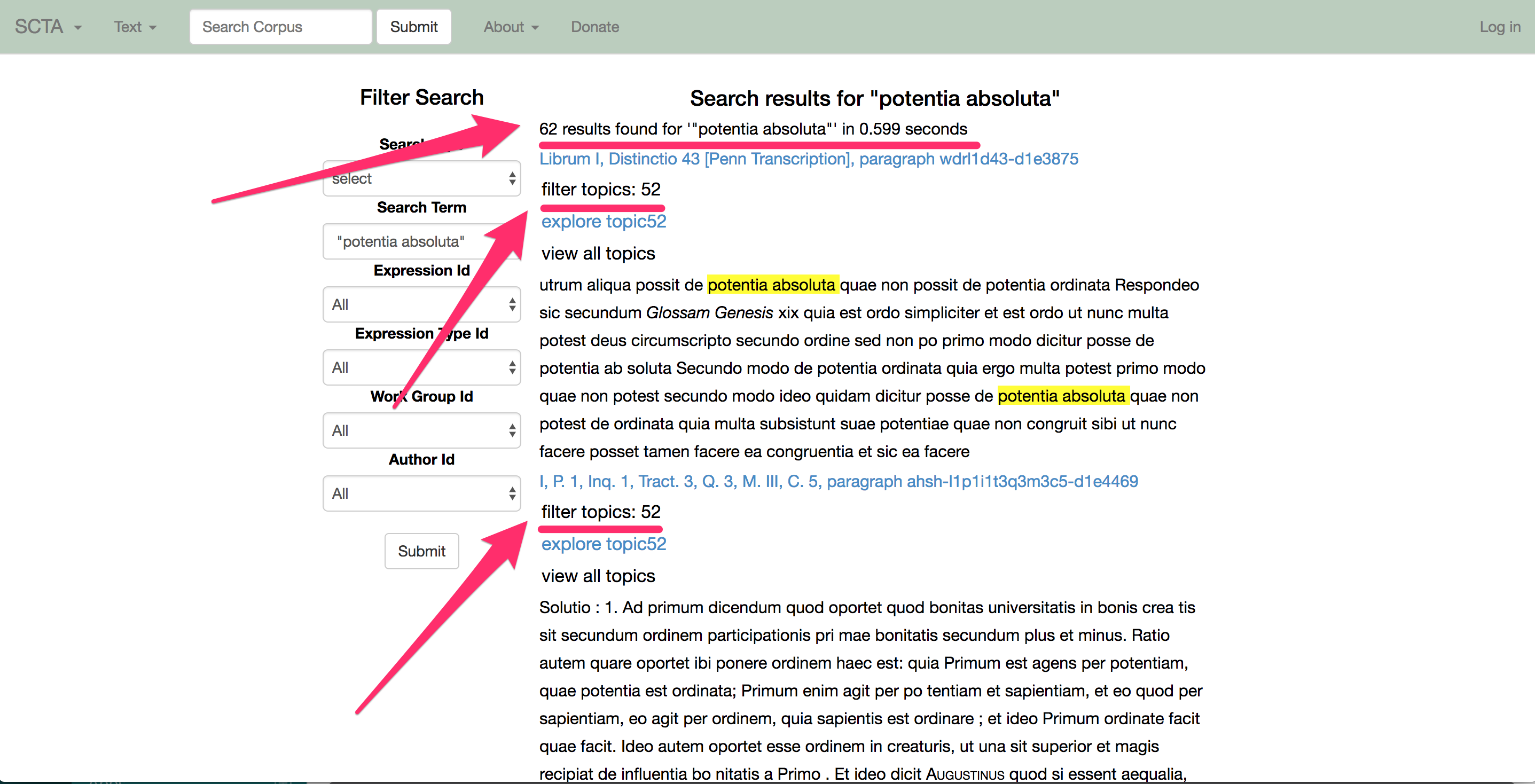
Die erste Idee, die ich hatte, war diese Abfrage zu nutzen, um, abhängig vom aktuellen Interesse des Lesers, empfohlene Verbindungen anzubieten.
Also, in dem Fall von einem Absatz von De Trinitate von Augustinus, unter der Liste von editorisch erkannten Zitaten (die wir oben gesehen haben), konnte der Computer eine Liste von ähnlichen Absätzen empfehlen.
Bild 8

Hier können das computergestützte Vorgehen und die editorische Arbeit kombiniert werden. Der Computer gibt uns eine Liste von ähnlichen Absätzen und erzählt uns, welche schon von Editoren markiert wurden und welche noch unbestätigt sind.
Diese Methode und Visualisierung sind sehr hilfreich, wenn man mit einer bestimmten Passage im Kopf beginnt. Wenn ich mich schon mit einem Text beschäftige, kann diese Methode auf andere nützliche Passagen hindeuten.
Aber was, wenn ich nicht weiß, wo ich beginnen soll? Was, wenn ich alle Nachnutzungen (nicht nur für eine bestimmte Passage) sehen will? Oder was, wenn ich darauf aufmerksam gemacht werden will, dass eine Passage (die mir vorher nicht bewusst war) wahrscheinlich eine Quelle von vielen Text-Nachnutzungen ist?
Für eine Weile habe ich versucht, diese obige Methode zu benutzen. Ich habe mich von Absatz zu Absatz bewegt, und manchmal habe ich etwas Interessantes gefunden, aber es war immer noch willkürlich.
Was mir gefehlt hat, war eine Vogelperspektive, um die ganze Landschaft zu sehen. Mit dieser Landschaft wollte ich Absätze sehen (von denen ich vorher keine Ahnung hatte), die Nachnutzung oder Einfluss zeigen.
Die Daten waren schon da.
Was ich gebraucht habe, war eine bessere Datenvisualisierung.
N-gram Visualization: Zweiter Versuch
Letzten Sommer habe ich eine coole “Javascript Library” gesehen, die entwickelt wurde, um die Unterschiede zwischen Handschriften-Zeugnisse zu visualisieren
Zuerst habe ich sie genau für diesen Zweck benutzt.
Hier, auf diesem Bild, haben wir jeden Absatz auf der X-Achse und jedes Zeugnis auf der Y-Achse abgebildet. Wir können den Unterschied zwischen jedem Absatz messen und dann diesen Unterschied mit blauer Farbe visualisieren.
Bild 9

Aber dann habe ich gedacht, ich brauche etwas Ähnliches, um diese Vogelperspektive zu sehen. Ich will alle Absätze gleichzeitig sehen, und dann darauf aufmerksam gemacht werden, wann und wo ein Absatz oder ein größerer Abschnitt mit anderen Texten verbunden ist.
Beispiel 1: Zitatsmuster-Entdeckung in der Tradition von den Sentenzen Kommentaren
Also hier auf dem nächsten Bild ist ein Beispiel, wieder mit dem De Trinitate von Augustinus.
Auf der X-Achse ist jeder Absatz in dem De Trinitate. Auf der Y-Achse ist jeder Absatz, der “Ähnlichkeit” mit dem Absatz auf der X-Achse hat.
Die Metadaten des Korpus Graph sind hier wichtig. Diese Absätze auf der Y-Achse sind zuerst in der Datumsfolge angeordnet und dann in der Reihenfolge innerhalb des jeweiligen Textes.
Bild 10

Mit der Datumsfolge können wir versuchen, Quellen und Einfluss zu unterscheiden. Hier auf diesem Bild (Bild 11), wenn einen Absatz von Augustinus Ähnlichkeit mit einem Text hat, der vor Augustinus geschrieben wurde, dann sehen wir diesen Absatz in Rot. Wenn der Absatz nach Augustinus geschrieben wurde, dann sehen wir diesen Absatz in Blau.
Bild 11

Entsprechend, wenn wir eine Spalte ohne Rot und viel Blau sehen, können wir ableiten, dass wir eine Passage sehen, die viel Einfluss hat, weil viele Leute Augustinus direkt zitiert haben.
Wir können auch die Metadaten nutzen, um unsere Vogelperspektive zu fokussieren, zum Beispiel um nur zwei Texte miteinander zu vergleichen.
Hier vergleichen wir den Text von Augustinus nur mit dem Text von Petrus Lombardus.
Was wir am klarsten sehen ist die häufige Nutzung des Mittelteils von De Trinitate und wieder die häufige Nutzung des Letzten Teils (z.B. Bücher 14 und 15).
Bild 12

Wir können auch diese Perspektive umkehren. Hier sehen wir den Text von Petrus Lombardus auf der X-Achse und Augustinus auf der Y-Achse. Ganz schnell sehen wir, dass die Nutzung von De Trinitate sehr früh in dem Text von Petrus Lombardus vorkommt, aber nicht zu oft im späteren Teil.
Bild 13

Außerdem können wir die Korpusdaten benutzen, um verschiedene Textgattungen zu vergleichen.
Hier zeigen wir wieder jeden Absatz von De Trinitate auf der X-Achse, aber dann vergleichen wir jeden Absatz nur mit jedem Absatz in einem Sentenzenkommentar. Die Farbe hilft uns, die unterschiedlichen Kommentaren zu unterscheiden.
Eine solche Perspektive erlaubt uns, Innovation in der Tradition zu erkennen. Wir können immer noch sehen, wie Lombard den Text von Augustinus benutzt hat. Aber jetzt können wir zusätzlich sehen, ob und wie spätere Kommentare diesem Muster gefolgt sind oder nicht. Allgemein setzt sich das Muster von Lombardus fort.
Bild 14

Aber es ist auch möglich, Stellen zu sehen, wo Passagen von Augustinus benutzt werden, die nicht von Lombard zitiert werden, und das zeigt uns Innovation.
Bild 15

In dem folgenden Bild (Bild 16), können wir noch mal die Nachnutzung in jedem Kommentar sehen, aber diesmal wird jeder Absatz in einem Kommentar von einer bestimmten Distinctio gruppiert, mit den Absätzen von anderen Kommentaren, die auch ein Teil derselben Distinctio sind. (z.B. alle Texte der Distinctio 1 (geschrieben vom 12ten bis zum 16ten Jahrhundert) werden zusammen gruppiert. Und danach werden alle Texte der Distinctio 2 (geschrieben vom 12ten. bis zum 16ten. Jahrhundert) zusammen gruppiert. Und so weiter und so fort).
Wir können ganz klar sehen, wie die spezifische Nutzung von “de Trinitate” verschiedenen Themen in verschiedenen Distinctiones entspricht.
Bild 16

Wir können auch sehen, wie die Nutzung in einer “Distinctio” eines Kommentars vom allgemeinen Muster abweicht, das in anderen Kommentaren in dieselbe Distinctio gesehen wird.
Bild 17

Und wenn wir einen Bereich von Interessen (wie diese) gefunden haben, können wir die Metadaten benutzen, um diesen Bereich zu vergrößern.
Hier konzentrieren wir uns nur auf Distinctio 8 in allen Kommentaren.
Wir können sehen, dass es ziemlich traditionell ist, Buch 5 in Distinctio 8 zu zitieren.
Aber später in der Tradition sehen wir Innovation. Plötzlich sehen wir Zitate aus dem Buch 15.
Bild 18

Oder in dem nächsten Bild, jeder Absatz in dem Text von Lombardus ist mit jedem Absatz in jedem Kommentar (wieder von derselben Distinctio gruppiert) verglichen.
Das zeigt uns meistens, was wir erwarten. In den Kommentaren auf Distinctio 1 sehen wir heftige Nachnutzung von Distinctio 1 von Lombardus.
Aber es hilft uns auch zu sehen, wo ein Autor anfängt, sich auf unerwartete Passagen zu verlassen.
Zum Beispiel, ein Kommentator, der kommentiert auf Distinctio 1, der plötzlich beginnt, Passagen von Distinctio 3 zu nutzen..
Bild 19

Beispiel 2: “UNCITED SUCCESSIVE PASSAGE RE-USE”
Schließlich ist hier noch ein anderes Beispiel, auf das ich für eine Weile fokussieren will.
Bislang haben wir uns auf die Nachnutzung von bestimmten isolierten Zitaten fokussiert.
Aber es gibt eine andere Art Nachnutzung in der Scholastischen Tradition. Diese nenne ich “Uncited Successive Passage Re-Use,” das heißt, was wir ein Plagiat nennen würden.
Dieses Bild zeigt uns etwas sehr Interessantes. Aber wir müssen lernen, die Ergebnisse zu lesen.
Bild 20

Bild 21

In diesem Fall wird die Bedeutung klarer sein, wenn wir eine kleine Erklärung über diesen Text und die vorherige Forschung an diesem Text haben.
Der Text auf der X-Achse ist ein Sentenz Kommentar von Petrus Gracilis, der den Text im späten 14. Jahrhundert geschrieben hat.
In 1956 findet Damasus Trapp heraus, dass dieser Text zahlreiche Nachnutzungen aus dem Text von John von Basel enthält.
Trapp schreibt nicht, welche Passagen genau nachgenutzt wurden. Er sagt nur, dass Gracilis meistens Basel kopiert.
Aber besonders wichtig für uns ist die Tatsache, dass Trapp zugibt, dass diese Entdeckung ein glücklicher Zufall war.
“Petrus Gracilis…followed not only the footsteps but the very phrases of Hiltalingen in a way so deceptive that it does not cast the best light on Gracilis. He read secundum Hiltalingen without ever mentioning him. Only by a lucky coincidence [emphasis mine] was I enabled to “unmask” Gracilis’ dubious literary honesty. (See Trapp, Damasus, “Augustinian Theology of the 14th Century,” Augustiniana 6 (1956): 147-274, p. 254.)
Das ist genau der Punkt. Die traditionelle Forschung zeigt Interesse für diese Art Forschungsfragen. Aber die Methoden sind anekdotisch und zufällig. Wir brauchen wissenschaftliche Methoden.
Dass die traditionelle Forschung dieser Art Fragen von der wissenschaftlichen Community wertgeschätzt wird, ist in einem Artikel von Venicio Marcolino von 2008 klar. Marcolino folgt Trapp und versucht die Verbindung zwischen Gracilis und Basel genauer zu machen.
Marcolino bewegt sich durch den Kommentar, Distinctio für Distinctio, Fragen für Fragen, und versucht zu zeigen, wo Gracilis den Text von Basel benutzt hat.
Über diesen Aufsatz (in dem Bild unten gesehen) können wir ein paar Dinge bemerken.
Zuerst ist der Text von Gracilis definitiv keine einfache Kopie von Basel und mischt viele andere Texte und auch viele originelle Wörter mit ein.
Zweitens gibt es viele Fragezeichen, wo Marcolino Nachnutzung erwartet, aber keine Quelle finden kann.
Drittens gibt es komplette Fragen, wo er keine Verbindung sieht, und, von dem Artikel, es sieht so aus, als ob er denkt, es gibt keine Abhängigkeit hier und der Leser soll sich wohl fühlen, abzuleiten, dass hier Gracilis original sein muss.
Bild 22

Also, lass uns zu unserer Datenvisualisierung zurückkommen.
Bild 23
In der Mitte dieses Graph können wir eine ziemlich große rote Schliere sehen. Günstigerweise entspricht diese rote Schliere dem Text von John von Basel. Der Computer zeigt uns automatisch, was Trappp und Marcolino bestätigen.
Aber mit der Hilfe des Text-Network können wir diese Abhängigkeit genauer und mit mehr Transparenz sehen. Mit einem Click, können wir jeden roten Punkt untersuchen.
Bild 24

Bild 25

Der Graph (Bild 26) zeigt uns auch die Lücke in der Nachnutzung. Genau dieser Punkt, wo Marcolino keine Abhängigkeit berichtet hat. (z.B. Frage 30, und 38)
Aber der Graph zeigt uns auch, was Marcolino nicht gewusst hat, und was niemand, ohne einen sehr glücklichen Zufall, nicht hätte wissen können.
Während Marcolino uns den Eindruck gibt, dass hier (in Fragen 30 und 38) Gracilis plötzlich keine Nachnutzung hat, zeigt uns der Graph, dass genau in diesem Punkt, wo keine Abhängigkeit auf Basel gesehen werden kann, sehr starke Abhängigkeit auf einem anderen Text gibt: den Text von Andreas de Novo Castro.
Bild 26

Ein weiterer Schritt.
Die Visualisierung zeigt uns ein interessantes Muster von Abhängigkeit: wenn es substantielle und kontinuierliche Nachnutzung gibt, sehen wir normalerweise ein diagonales Muster. Wenn die Nachnutzung groß ist, wie im Fall von Basel, ist das Muster einfach zu sehen. Aber wenn es kleiner ist und die Vogelperspektive sehr weit ist, kann es schwieriger zu sehen sein.
Aber jetzt, da wir dieses Muster kennen, können wir den Daten Graph benutzen, um dieses Muster im gesamten Korpus algorithmisch durchzusuchen.
| 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
|---|---|---|---|---|---|---|---|---|
| 2 | ||||||||
| 3 | ||||||||
| 4 | x | |||||||
| 5 | x | |||||||
| 6 | x | |||||||
| 7 | ||||||||
| 8 | ||||||||
| 9 |
Genauer gesagt, ein diagonales Muster in dieser Anordnung bedeutet, dass wenn wir von einem Absatz beginnen, der Ähnlichkeit mit einem anderen Absatz hat, dann, wenn wir uns vorwärts bewegen (zum nächsten Absatz, auf der X-Achse), finden wir ähnlichkeit zwischen diesem Absatz und dem nächsten Absatz auf der Y-Achse.
Wir können es so beschreiben.
\[SuccessiveReuse(t) =\] \[\forall{x_n}\forall{y_m}(R(x_{n}, y_{m}) \land R(x_{n+1}, y_{m+1}) \land R(x_{n+2},y_{m+2}))\]Wir können es ein bisschen ungenauer machen, damit es mehr Clusters findet.
\[SuccessiveReuse(t) =\] \[\forall{x_n}\forall{y_m}(R(x_n,y_m)\] \[\land (R(x_{n+1},y_{m+1}) \lor R(x_{n+2},y_{m+2}))\] \[\land (R(x_{n+3},y_{m+2}) \lor (R(x_{n+4},y_{m+3}))\] \[\land (R(x_{n+3},y_{m+3}) \lor (R(x_{n+4},y_{m+4}))\]Schließlich, um unsere Ergebnisse zu filtern, können wir ein Threshold innerhalb eines bestimmten Bereiches setzen, um die Stellen, wo viele Clusters sind, zu isolieren. In diesen Beispielen suche ich noch bestimmte Fragen oder Kapitel, die 10 oder mehr Clusters haben.
Also:
\[SubstantialSuccessiveReuse(t) =\] \[\#\{ a | \forall{t}(SuccessveReuse(t)\} >= 10\]where t = Question or Chapter
Die algorithmisch entdeckten Clusters helfen uns, Nachnutzung zu sehen, die in der Visualisierung schwierig zu sehen sind. Und damit können wir eine zweite Entdeckung machen.
Hier haben wir einen großen Abschnitt von die Summa von Albertus Magnus. Albertus hat so viele Zitate und so viel Einfluss, dass es schwierig ist, einzelne Clusters von fortgesetzte Text-Nachnutzung zu isolieren und zu untersuchen.

Aber innerhalb dieses Morasts kann der Algorithmus Clusters berichten. Hier innerhalb einer Frage von Albertus hat der Computer eine andere Frage von einem sehr unbekannten Autor (Lambertus de Monte), der im 15 Jahrhundert geschrieben hat, der mindestens 22 Clusters von Nachnutzung hat.
Bild 27

Und jetzt, dass wir ein Cluster von Interesse gefunden haben, mit der Hilfe der Metadaten in dem Korpus-Graph, können wir die Visualisierung fokussieren und diese Nachnutzung genauer untersuchen.
Bild 28

Das hier ist noch eine echte Entdeckung. Nirgendwo hat Lambertus den Namen von Albertus erwähnt. Er hat kein Zeichen von Zitierung gegeben. Er hat geschrieben, als ob diese Wörter seine eigenen wären. Aber der Computer findet diese Nachnutzung ohne Mühe.
Auf diese Weise kann ich, ohne Vorwissen, den ganzen Korpus überfliegen und Nachnutzung und Einfluss in den Texten entdecken, von denen ich vorher keine Ahnung hatte.
Hier ist ein Bericht von jedem Text in dem Korpus, mit einer Liste von anderen Texten, die eine Cluster Zahl größer als 10 haben.
Bild 29

Bild 30

Und mit diesem Bericht können wir diesen Korpus überfliegen und die Ergebnisse untersuchen und mehr Entdeckungen machen.
]]>
















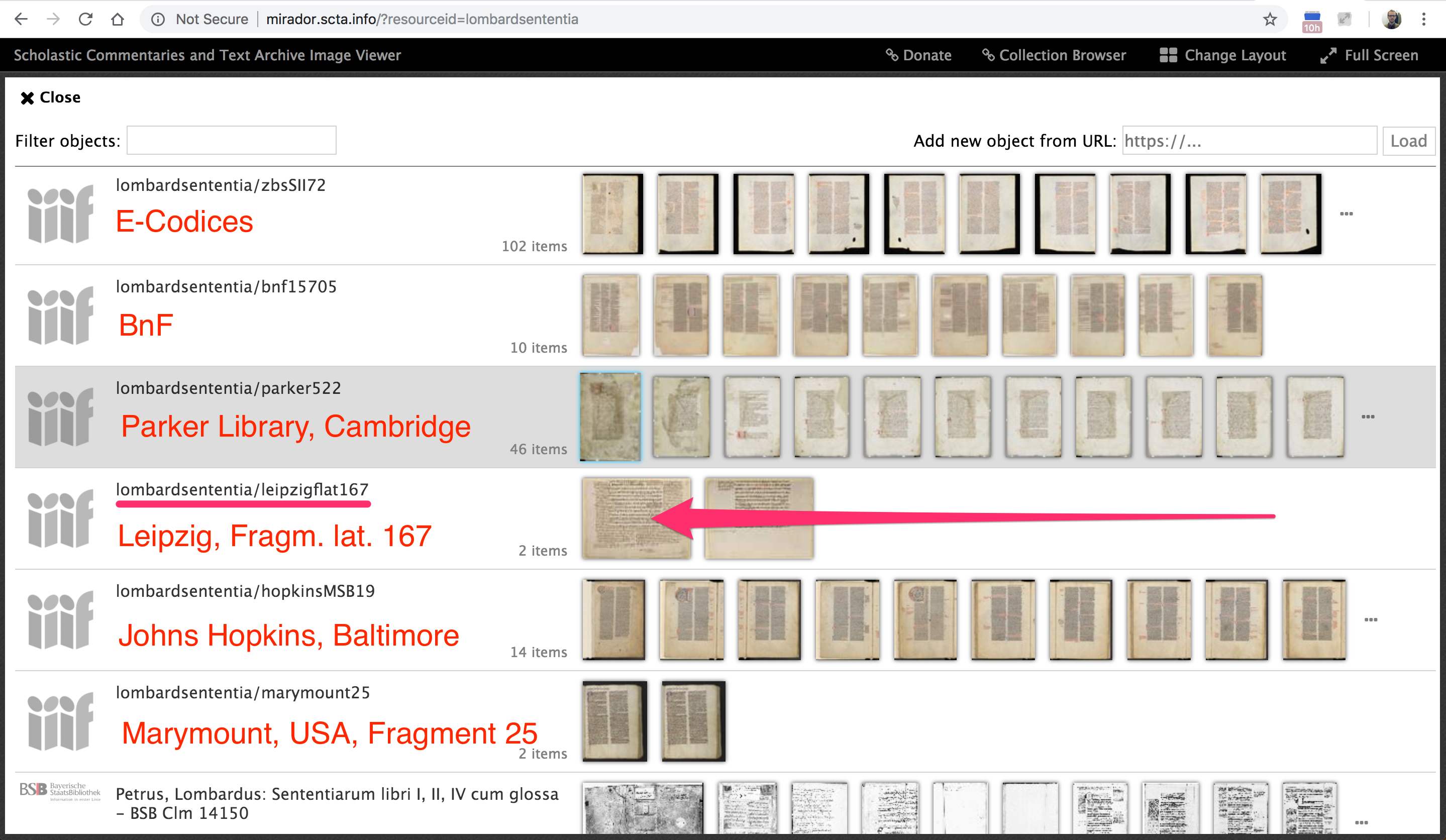
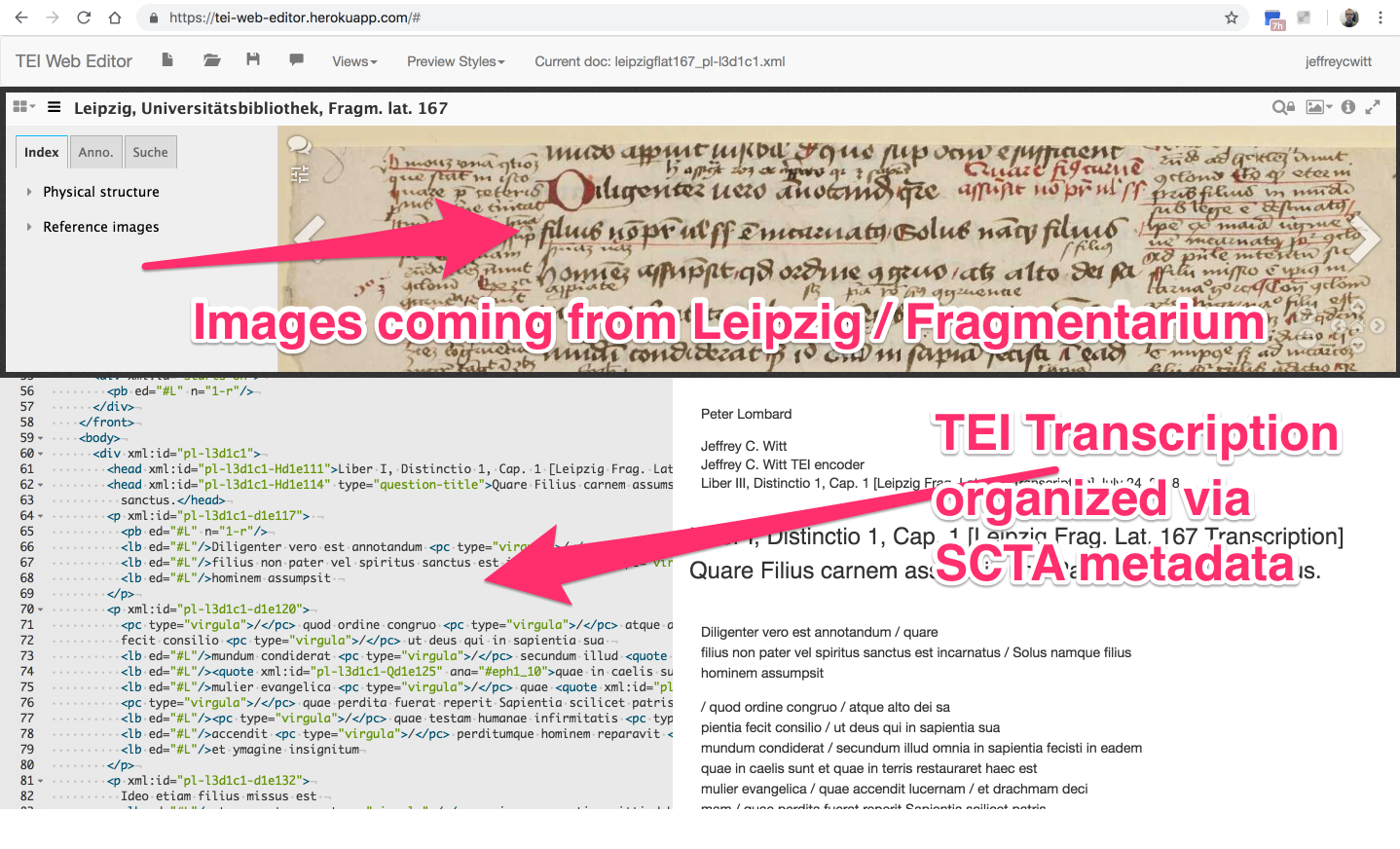
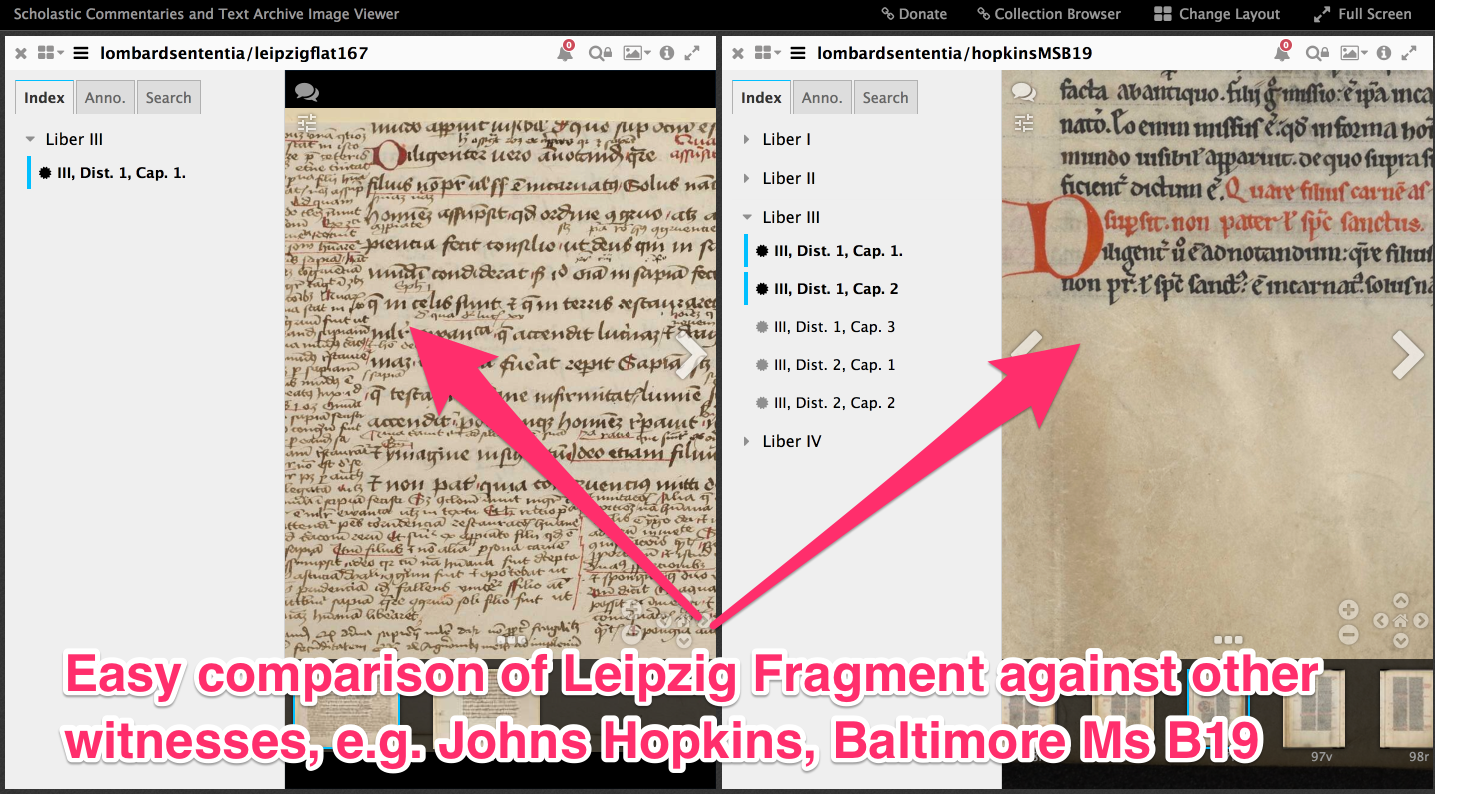
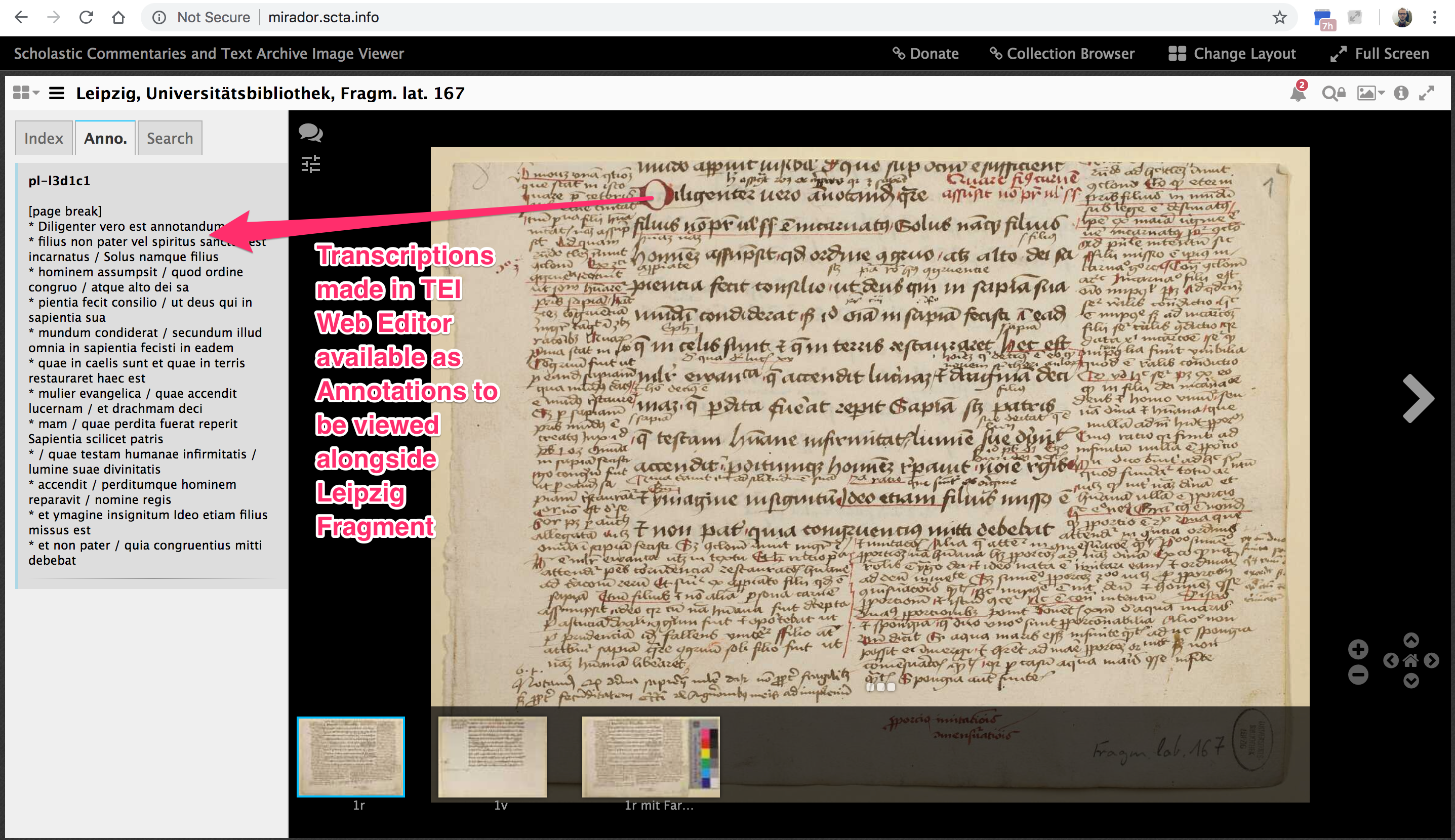
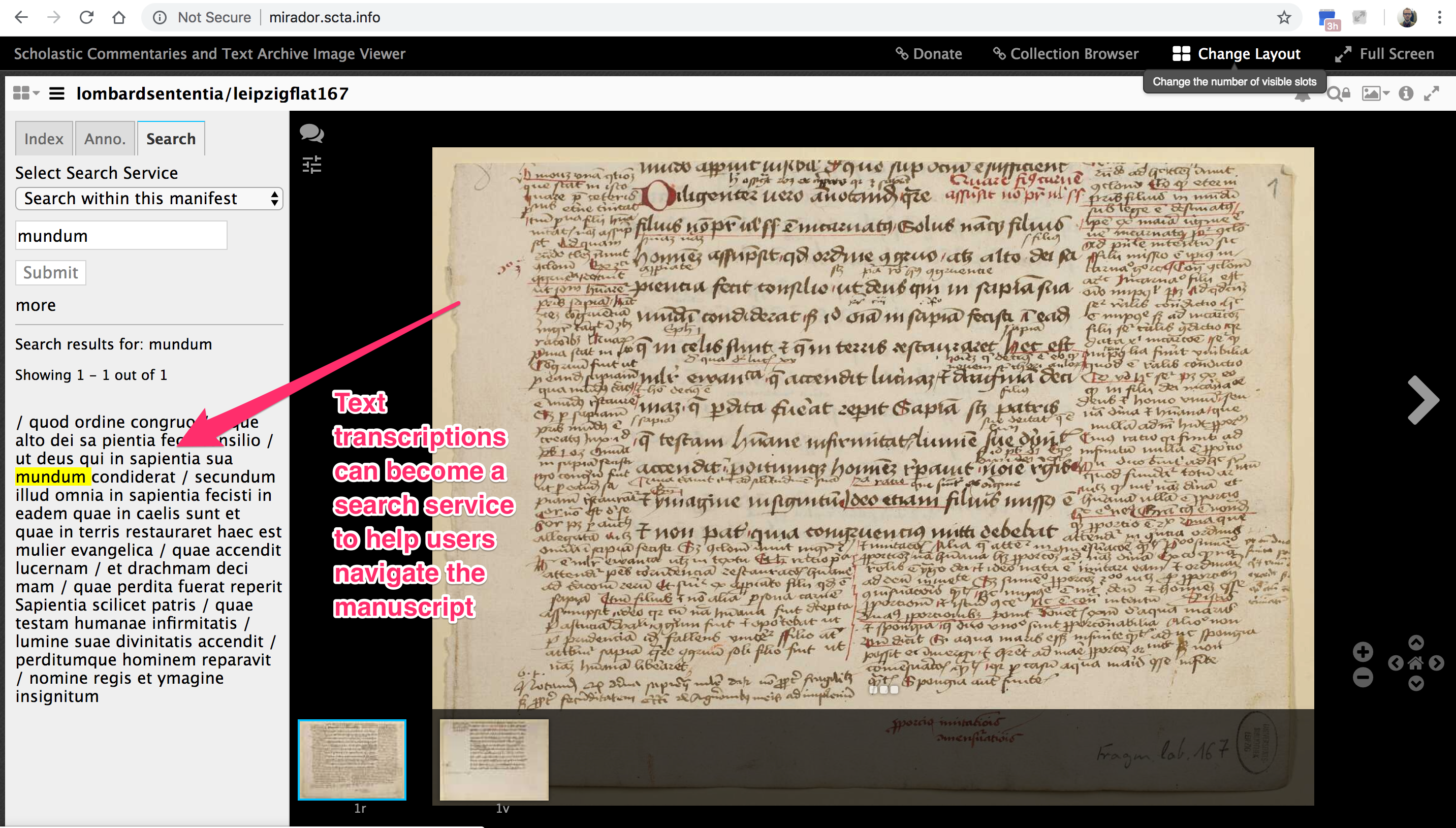



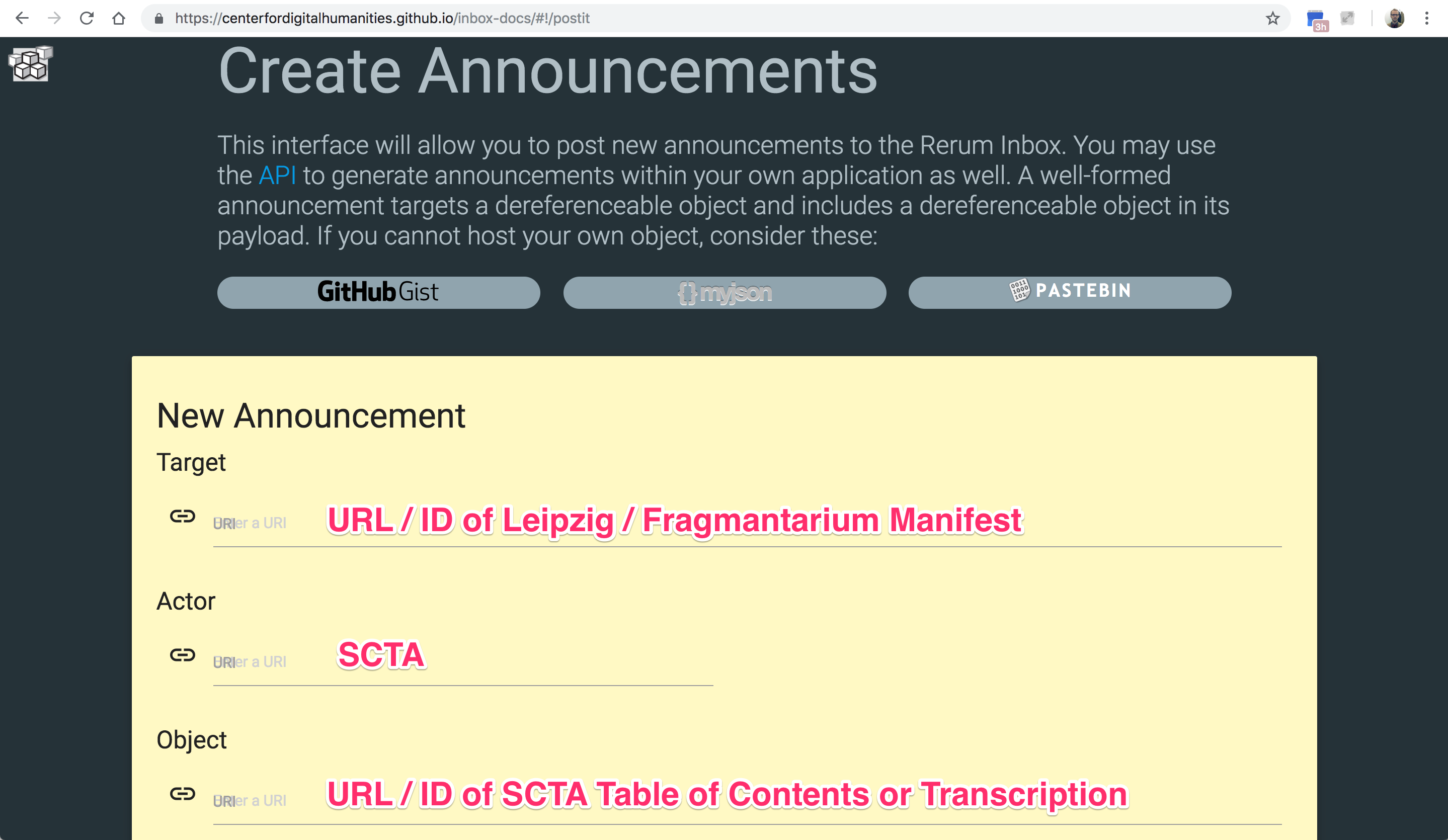

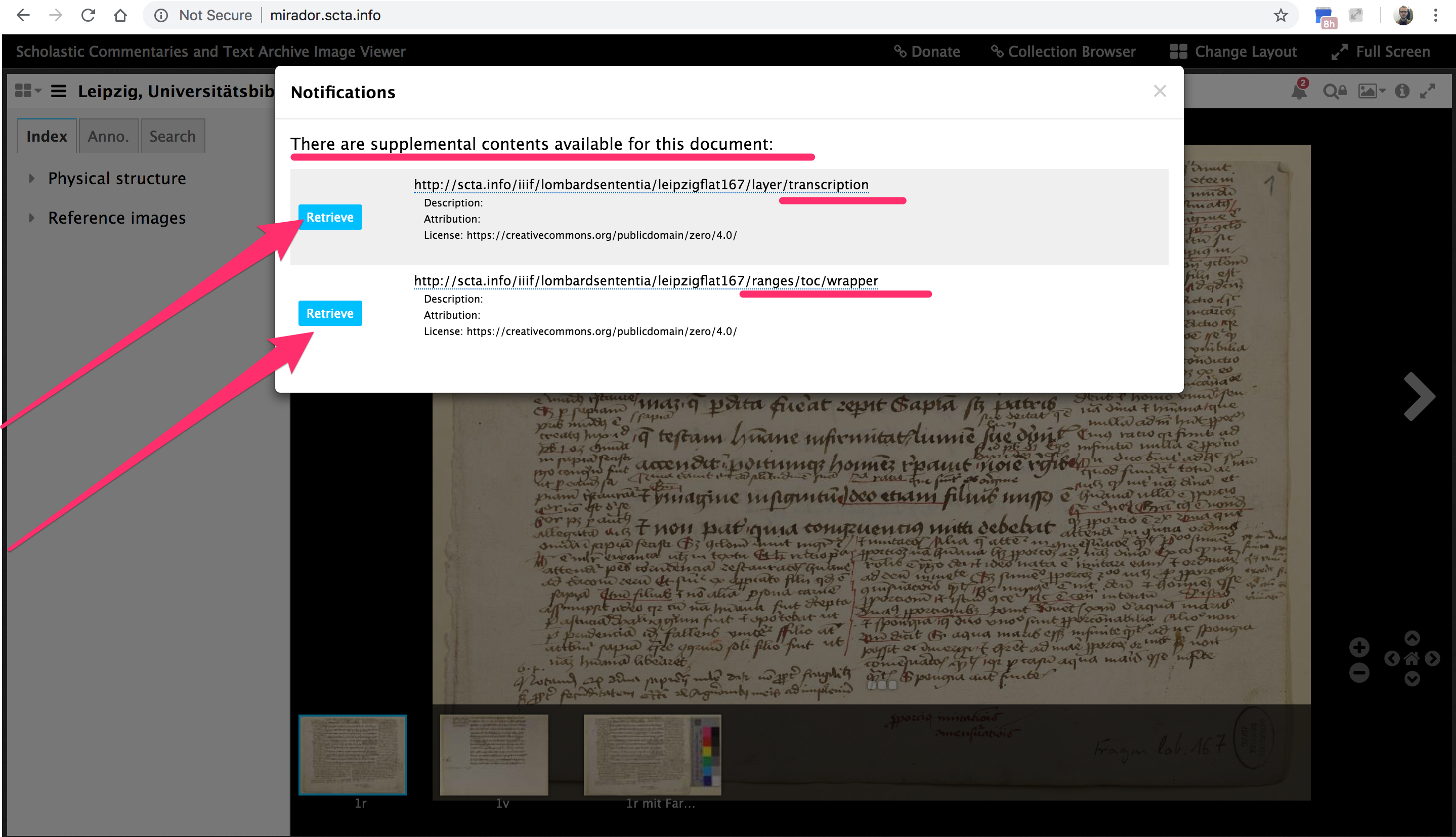 Aber jetzt nach meiner Mitteilung kann ein Nutzer, ohne mich oder die SCTA zu kennen, per Klick eine Liste von verfügbaren ergänzenden Forschungsdaten bekommen.
Aber jetzt nach meiner Mitteilung kann ein Nutzer, ohne mich oder die SCTA zu kennen, per Klick eine Liste von verfügbaren ergänzenden Forschungsdaten bekommen.